
Модуль Python Селена построен для выполнения автоматического тестирования с помощью Python. Привязки Selenium Python предоставляют простой API для написания функциональных/приемочных тестов с использованием Selenium WebDriver. После того, как вы установили selenium и проверили – Переход по ссылкам с помощью метода get, возможно, вам захочется больше играть с Selenium Python. После того, как вы открыли страницу с помощью selenium, например geeksforgeeks, вам может потребоваться автоматически нажать некоторые кнопки или заполнить форму автоматически или выполнить любую подобную автоматическую задачу.
Эта статья посвящена тому, как захватить или найти элементы на веб-странице с помощью стратегий поиска веб-драйвера Selenium. Более конкретно, функция find_element_by_link_text() обсуждается в этой статье. При использовании этой стратегии будет возвращен первый элемент со значением текста ссылки, соответствующим местоположению. Если ни один элемент не имеет соответствующего атрибута текста ссылки, будет вызвано исключение NoSuchElementException.
Синтаксис:
driver.find_element_by_link_text("Text of Link")Пример:
Например, рассмотрим этот источник страницы:
<html>
<body>
<p>Are you sure you want to do this?</p>
<a href="continue.html">Continue</a>
<a href="cancel.html">Cancel</a>
</body>
<html>
Теперь, после того как вы создали драйвер, вы можете захватить элемент с помощью:
login_form = driver.find_element_by_link_text('Continue')Как использовать метод driver.find_element_by_link_text() в Selenium?
Давайте попробуем практически реализовать этот метод и получим экземпляр элемента для “https://www.yandex.ru/”. Давайте попробуем захватить ввод формы поиска, используя ее текст ссылки “Учебники”.
Создайте файл с именем run.py чтобы продемонстрировать метод find_element_by_link_text:
# Python program to demonstrate
# selenium
# import webdriver
from selenium import webdriver
# create webdriver object
driver = webdriver.Firefox()
# enter keyword to search
keyword = "yandex"
# get yandex.ru
driver.get("https://www.yandex.ru/")
# get element
element = driver.find_element_by_link_text("Tutorials")
# print complete element
print(element)
Теперь запустите с помощью:
Python run.pyСначала он откроет окно firefox с yandex, а затем выберет элемент и распечатает его на терминале, как показано ниже.
Вывод браузера:
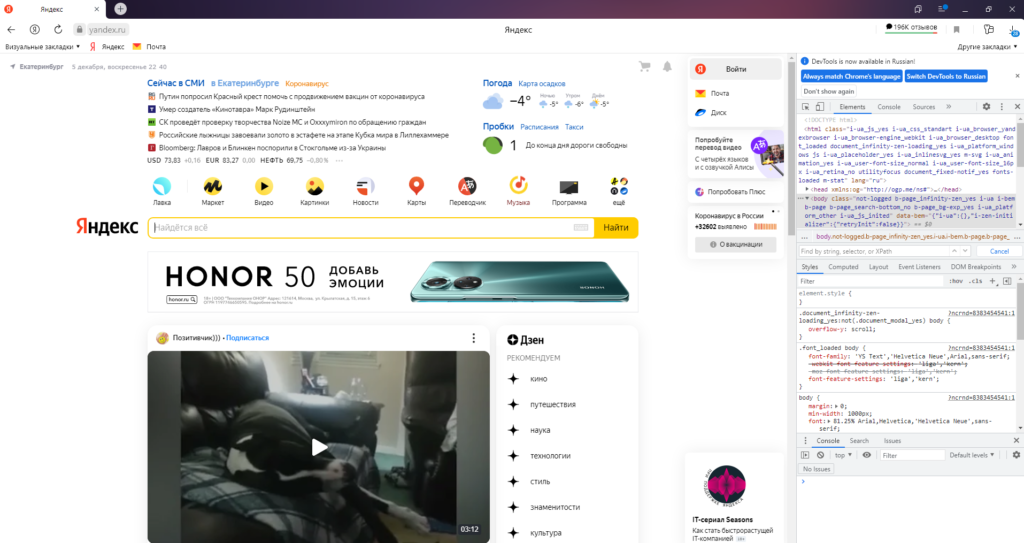
Клеммный Выход:

Больше локаторов для определения местоположения отдельных элементов
| ЛОКАТОРЫ | ОПИСАНИЕ |
|---|---|
| find_element_by_id | Будет возвращен первый элемент со значением атрибута id, соответствующим местоположению. |
| find_element_by_name | Будет возвращен первый элемент со значением атрибута name, соответствующим местоположению. |
| find_element_by_xpath | Будет возвращен первый элемент с синтаксисом xpath, соответствующим местоположению. |
| find_element_by_link_text | Будет возвращен первый элемент со значением текста ссылки, соответствующим местоположению. |
| find_element_by_partial_link_text | Будет возвращен первый элемент со значением текста частичной ссылки, соответствующим местоположению. |
| find_element_by_tag_name | Будет возвращен первый элемент с заданным именем тега. |
| find_element_by_class_name | будет возвращен первый элемент с соответствующим именем атрибута класса. |
| find_element_by_css_selector | Будет возвращен первый элемент с соответствующим селектором CSS. |

