
Эта статья представляет собой краткое введение в многопроцессорную обработку на языке программирования Python.
Что такое многопроцессорная обработка?
Многопроцессорная обработка относится к способности системы поддерживать несколько процессоров одновременно. Приложения в многопроцессорной системе разбиваются на более мелкие подпрограммы, которые выполняются независимо. Операционная система распределяет эти потоки процессорам, повышая производительность системы.
Почему многопроцессорная обработка?
Рассмотрим компьютерную систему с одним процессором. Если ему назначено несколько процессов одновременно, ему придется прерывать каждую задачу и ненадолго переключаться на другую, чтобы все процессы продолжались.
Эта ситуация похожа на то, как шеф-повар работает на кухне в одиночку. Он должен выполнить несколько задач, таких как выпечка, перемешивание, замес теста и т. д.
Итак, суть в том, что: Чем больше задач вы должны выполнить одновременно, тем труднее становится отслеживать их все, и соблюдение правильного времени становится все более сложной задачей.
Именно здесь возникает концепция многопроцессорной обработки!
Многопроцессорная система может иметь:
- многопроцессорный, т. е. компьютер с более чем одним центральным процессором.
- многоядерный процессор, т. е. один вычислительный компонент с двумя или более независимыми фактическими процессорами (называемыми “ядрами”).
Здесь центральный процессор может легко выполнять несколько задач одновременно, причем каждая задача использует свой собственный процессор.
Это похоже на то, как шеф-повару в прошлой ситуации помогают его помощники. Теперь они могут делить задачи между собой, и шеф-повару не нужно переключаться между своими задачами.
Многопроцессорная обработка в Python
В Python, то многопроцессорная обработка модуль включает в себя очень простой и интуитивно понятный API для разделения работы между несколькими процессами.
Рассмотрим простой пример использования многопроцессорного модуля:
# importing the multiprocessing module
import multiprocessing
def print_cube(num):
"""
function to print cube of given num
"""
print("Cube: {}".format(num * num * num))
def print_square(num):
"""
function to print square of given num
"""
print("Square: {}".format(num * num))
if __name__ == "__main__":
# creating processes
p1 = multiprocessing.Process(target=print_square, args=(10, ))
p2 = multiprocessing.Process(target=print_cube, args=(10, ))
# starting process 1
p1.start()
# starting process 2
p2.start()
# wait until process 1 is finished
p1.join()
# wait until process 2 is finished
p2.join()
# both processes finished
print("Done!")
Square: 100
Cube: 1000
Done!Давайте попробуем разобраться в приведенном выше коде:
- Чтобы импортировать модуль многопроцессорной обработки, мы делаем:
import multiprocessing- Чтобы создать процесс, мы создаем объект класса Process. Для этого требуются следующие аргументы:
- target: функция, которая будет выполняться процессом
- args: аргументы, которые должны быть переданы целевой функции
Примечание: Конструктор процесса также принимает множество других аргументов, которые будут обсуждаться позже. В приведенном выше примере мы создали 2 процесса с разными целевыми функциями:
p1 = multiprocessing.Process(target=print_square, args=(10, ))
p2 = multiprocessing.Process(target=print_cube, args=(10, ))- Чтобы запустить процесс, мы используем способ запуска Класс процесса.
p1.start()
p2.start()- После запуска процессов текущая программа также продолжает выполняться. Чтобы остановить выполнение текущей программы до завершения процесса, мы используем метод join.
p1.join()
p2.join()- В результате текущая программа сначала дождется завершения р1 и затем р2. Как только они будут завершены, будут выполнены следующие инструкции текущей программы.
Давайте рассмотрим другую программу, чтобы понять концепцию различных процессов, выполняемых на одном и том же скрипте python. В приведенном ниже примере мы печатаем идентификатор процессов, выполняющих целевые функции:
# importing the multiprocessing module
import multiprocessing
import os
def worker1():
# printing process id
print("ID of process running worker1: {}".format(os.getpid()))
def worker2():
# printing process id
print("ID of process running worker2: {}".format(os.getpid()))
if __name__ == "__main__":
# printing main program process id
print("ID of main process: {}".format(os.getpid()))
# creating processes
p1 = multiprocessing.Process(target=worker1)
p2 = multiprocessing.Process(target=worker2)
# starting processes
p1.start()
p2.start()
# process IDs
print("ID of process p1: {}".format(p1.pid))
print("ID of process p2: {}".format(p2.pid))
# wait until processes are finished
p1.join()
p2.join()
# both processes finished
print("Both processes finished execution!")
# check if processes are alive
print("Process p1 is alive: {}".format(p1.is_alive()))
print("Process p2 is alive: {}".format(p2.is_alive()))
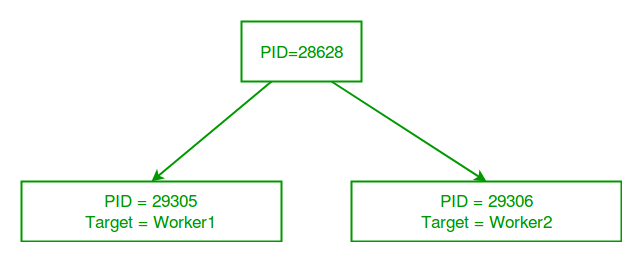
ID of main process: 28628
ID of process running worker1: 29305
ID of process running worker2: 29306
ID of process p1: 29305
ID of process p2: 29306
Both processes finished execution!
Process p1 is alive: False
Process p2 is alive: False- Основной скрипт python имеет другой идентификатор процесса, а модуль многопроцессорной обработки создает новые процессы с другими идентификаторами процессов по мере создания Объекты процесса р1 и р2. В приведенной выше программе мы используем os.getpid() функция для получения идентификатора процесса, выполняющего текущую целевую функцию.Обратите внимание, что он совпадает с идентификаторами процессов р1 и р2 которые мы получаем с помощью атрибут pid Класс процесса.
- Каждый процесс выполняется независимо и имеет свое собственное пространство памяти.
- Как только выполнение целевой функции завершается, процессы завершаются. В приведенной выше программе мы использовали is_alive метод Класс процесса, чтобы проверить, все еще активен процесс или нет.
Рассмотрим диаграмму ниже, чтобы понять, чем новые процессы отличаются от основного скрипта Python:
Итак, это было краткое введение в многопроцессорную обработку в Python. Следующие несколько статей будут посвящены следующим темам, связанным с многопроцессорной обработкой:
- Обмен данными между процессами с использованием массива, значения и очередей.
- Концепции блокировки и пула в многопроцессорной обработке
Рекомендации:
