
Эта статья посвящена тому, как можно проанализировать данный XML-файл и извлечь из него некоторые полезные данные структурированным способом.
XML: XML означает расширяемый язык разметки. Он был разработан для хранения и транспортировки данных. Он был разработан таким образом, чтобы его можно было читать как человеком, так и машиной.Вот почему цели дизайна XML подчеркивают простоту, универсальность и удобство использования в Интернете.
XML-файл, который будет проанализирован в этом руководстве, на самом деле является RSS-каналом.
RSS: RSS(Расширенная сводка сайта, часто называемая Действительно простой с индикацией) использует семейство стандартных форматов веб-каналов для публикации часто обновляемой информации, такой как записи в блоге, заголовки новостей, аудио, видео. RSS-это обычный текст в формате XML.
- Сам формат RSS относительно легко читается как автоматизированными процессами, так и людьми.
- RSS-канал, обработанный в этом руководстве, представляет собой RSS-канал главных новостей с популярного новостного веб-сайта. Вы можете проверить это здесь. Наша цель-обработать этот RSS-канал (или XML-файл) и сохранить его в каком-либо другом формате для дальнейшего использования.
Используемый модуль Python: Эта статья будет посвящена использованию встроенного xml-модуля в python для анализа XML, и основное внимание будет уделено XML-API ElementTree этого модуля.
Реализация:
#Python code to illustrate parsing of XML files
# importing the required modules
import csv
import requests
import xml.etree.ElementTree as ET
def loadRSS():
# url of rss feed
url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml'
# creating HTTP response object from given url
resp = requests.get(url)
# saving the xml file
with open('topnewsfeed.xml', 'wb') as f:
f.write(resp.content)
def parseXML(xmlfile):
# create element tree object
tree = ET.parse(xmlfile)
# get root element
root = tree.getroot()
# create empty list for news items
newsitems = []
# iterate news items
for item in root.findall('./channel/item'):
# empty news dictionary
news = {}
# iterate child elements of item
for child in item:
# special checking for namespace object content:media
if child.tag == '{http://search.yahoo.com/mrss/}content':
news['media'] = child.attrib['url']
else:
news[child.tag] = child.text.encode('utf8')
# append news dictionary to news items list
newsitems.append(news)
# return news items list
return newsitems
def savetoCSV(newsitems, filename):
# specifying the fields for csv file
fields = ['guid', 'title', 'pubDate', 'description', 'link', 'media']
# writing to csv file
with open(filename, 'w') as csvfile:
# creating a csv dict writer object
writer = csv.DictWriter(csvfile, fieldnames = fields)
# writing headers (field names)
writer.writeheader()
# writing data rows
writer.writerows(newsitems)
def main():
# load rss from web to update existing xml file
loadRSS()
# parse xml file
newsitems = parseXML('topnewsfeed.xml')
# store news items in a csv file
savetoCSV(newsitems, 'topnews.csv')
if __name__ == "__main__":
# calling main function
main()
Приведенный выше код будет:
- Загрузите RSS-канал с указанного URL-адреса и сохраните его в виде XML-файла.
- Проанализируйте XML-файл, чтобы сохранить новости в виде списка словарей, где каждый словарь представляет собой одну новость.
- Сохраните новости в CSV-файл.
Давайте попробуем разобраться в коде по частям:
- Загрузка и сохранение RSS-ленты
def loadRSS():
# url of rss feed
url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml'
# creating HTTP response object from given url
resp = requests.get(url)
# saving the xml file
with open('topnewsfeed.xml', 'wb') as f:
f.write(resp.content)Здесь мы сначала создали объект HTTP-ответа, отправив HTTP-запрос на URL-адрес RSS-канала. Содержимое ответа теперь содержит данные XML-файла, которые мы сохраняем как topnewsfeed.xml в нашем локальном каталоге.
- Синтаксический анализ XML
Мы создали Функция parseXML() для анализа XML-файла. Мы знаем, что XML по своей сути является иерархическим форматом данных, и наиболее естественным способом его представления является дерево. Посмотрите, например, на изображение ниже:
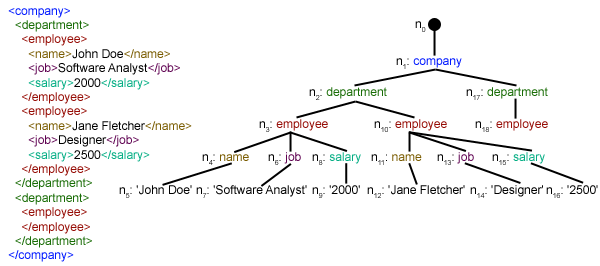
Здесь мы используем xml.etree.ElementTree (короче говоря, назовите это ET) модуль. Дерево элементов имеет для этой цели два класса – Element представляет весь XML
документ в виде дерева и Элемент представляет один узел в этом дереве. Взаимодействие со всем документом (чтение и запись в/из файлов) обычно выполняется на Уровень дерева элементов. Взаимодействия с одним XML-элементом и его под элементами выполняются на Element.
Хорошо, давайте пройдемся по parseXML() :
tree = ET.parse(xmlfile)Здесь мы создаем Объект ElementTree путем анализа переданного xmlfile.
root = tree.getroot()getroot() функция возвращает корень из дерево в качестве Элемент объекта.
for item in root.findall('./channel/item'):Теперь, как только вы взглянете на структуру вашего XML-файла, вы заметите, что нас интересует только элемент элемента.
./channel/item это на самом деле Синтаксис XPath (XPath-это язык для адресации частей XML-документа). Здесь мы хотим найти все item внуки channel children of the root (обозначается символом ‘.’) элемент.
Вы можете прочитать больше о поддерживаемом синтаксисе XPath здесь.
for item in root.findall('./channel/item'):
# empty news dictionary
news = {}
# iterate child elements of item
for child in item:
# special checking for namespace object content:media
if child.tag == '{http://search.yahoo.com/mrss/}content':
news['media'] = child.attrib['url']
else:
news[child.tag] = child.text.encode('utf8')
# append news dictionary to news items list
newsitems.append(news)Теперь мы знаем, что мы перебираем item элемента, где каждый item элемента содержит одну новость. Итак, мы создаем пустой словарь новостей, в котором будем хранить все доступные данные о новостях. Чтобы выполнить итерацию по каждому дочернему элементу элемента, мы просто повторяем его, вот так:
for child in item:Теперь обратите внимание на образец элемента элемента здесь:

Нам придется обрабатывать теги пространства имен отдельно по мере их расширения до исходного значения при анализе. Итак, мы делаем что-то вроде этого:
if child.tag == '{http://search.yahoo.com/mrss/}content':
news['media'] = child.attrib['url']child.attrib — это словарь всех атрибутов, связанных с элементом. Здесь нас интересует атрибут url-адреса тега пространства имен media:content.
Теперь для всех остальных детей мы просто делаем:
news[child.tag] = child.text.encode('utf8')child.tag содержит имя дочернего элемента. child.text сохраняет весь текст внутри этого дочернего элемента. Итак, наконец, пример элемента элемента преобразуется в словарь и выглядит следующим образом:
{'description': 'Ignis has a tough competition already, from Hyun.... ,
'guid': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... ,
'link': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... ,
'media': 'http://www.hindustantimes.com/rf/image_size_630x354/HT/... ,
'pubDate': 'Thu, 12 Jan 2017 12:33:04 GMT ',
'title': 'Maruti Ignis launches on Jan 13: Five cars that threa..... }Затем мы просто добавим этот элемент dict в элементы новостей списка.
наконец, этот список будет возвращен.
- Сохранение данных в CSV-файл
Теперь мы просто сохраняем список новостей в CSV-файл, чтобы его можно было легко использовать или изменять в будущем с помощью savetoCSV() функция. Чтобы узнать больше о записи элементов словаря в CSV-файл, ознакомьтесь с этой статьей:
Работа с CSV-файлами на Python
Итак, вот как теперь выглядят наши отформатированные данные:
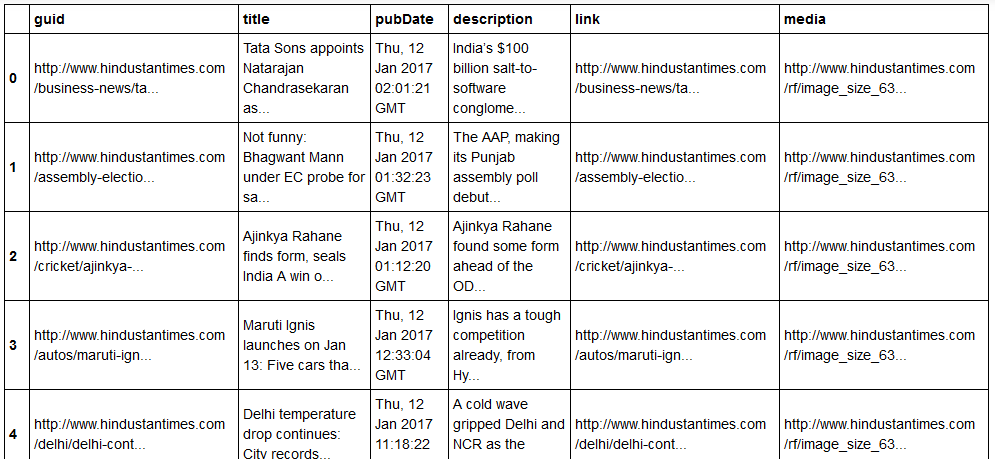
Как вы можете видеть, данные иерархического XML-файла были преобразованы в простой CSV-файл, так что все новости хранятся в виде таблицы. Это также облегчает расширение базы данных.
Кроме того, можно использовать данные, подобные JSON, непосредственно в своих приложениях! Это лучшая альтернатива для извлечения данных с веб-сайтов, которые не предоставляют общедоступный API, но предоставляют некоторые RSS-каналы.
Весь код и файлы, используемые в приведенной выше статье, можно найти здесь.


