Расширяемый язык разметки, широко известный как XML, — это язык, разработанный специально для того, чтобы его было легко интерпретировать как людям, так и компьютерам в целом. Язык определяет набор правил, используемых для кодирования документа в определенном формате. В этой статье были описаны методы чтения и записи XML-файлов на python.
Примечание: В общем случае процесс чтения данных из XML-файла и анализа его логических компонентов известен как синтаксический анализ. Поэтому, когда мы говорим о чтении XML-файла, мы имеем в виду анализ XML-документа.
В этой статье мы рассмотрим две библиотеки, которые можно использовать для анализа xml. Они являются:
- BeautifulSoup используется вместе с синтаксическим анализатором XML lxml
- Библиотека дерева элементов.
Использование BeautifulSoup вместе с синтаксическим анализатором lxml
Для чтения и записи XML-файла мы будем использовать библиотеку Python с именем BeautifulSoup. Чтобы установить библиотеку, введите в терминал следующую команду.
pip install beautifulsoup4Beautiful Soup поддерживает синтаксический анализатор HTML, включенный в стандартную библиотеку Python, но он также поддерживает ряд сторонних анализаторов Python. Один из них-синтаксический анализатор lxml (используется для анализа XML/HTML документов). lxml можно установить, выполнив следующую команду в командном процессоре вашей операционной системы:
pip install lxmlВо-первых, мы научимся читать из XML-файла. Мы также проанализировали бы данные, хранящиеся в нем. Позже мы узнаем, как создать XML-файл и записать в него данные.
Чтение Данных Из XML-Файла
Для анализа xml-файла требуется выполнить два шага:
- Поиск тегов
- Извлечение из тегов
Пример:
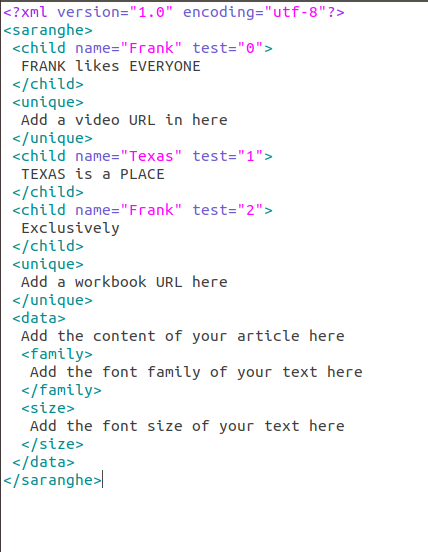
Используемый XML-файл:
from bs4 import BeautifulSoup
# Reading the data inside the xml
# file to a variable under the name
# data
with open('dict.xml', 'r') as f:
data = f.read()
# Passing the stored data inside
# the beautifulsoup parser, storing
# the returned object
Bs_data = BeautifulSoup(data, "xml")
# Finding all instances of tag
# `unique`
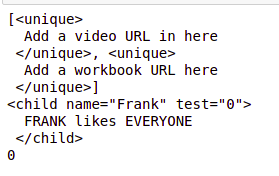
b_unique = Bs_data.find_all('unique')
print(b_unique)
# Using find() to extract attributes
# of the first instance of the tag
b_name = Bs_data.find('child', {'name':'Frank'})
print(b_name)
# Extracting the data stored in a
# specific attribute of the
# `child` tag
value = b_name.get('test')
print(value)
Выход:
Запись XML — файла
Написание xml-файла-это примитивный процесс, причиной которого является тот факт, что xml-файлы не кодируются особым образом. Изменение разделов xml-документа требует, чтобы сначала его проанализировали. В приведенном ниже коде мы изменим некоторые разделы вышеупомянутого xml-документа.
Пример:
from bs4 import BeautifulSoup
# Reading data from the xml file
with open('dict.xml', 'r') as f:
data = f.read()
# Passing the data of the xml
# file to the xml parser of
# beautifulsoup
bs_data = BeautifulSoup(data, 'xml')
# A loop for replacing the value
# of attribute `test` to WHAT !!
# The tag is found by the clause
# `bs_data.find_all('child', {'name':'Frank'})`
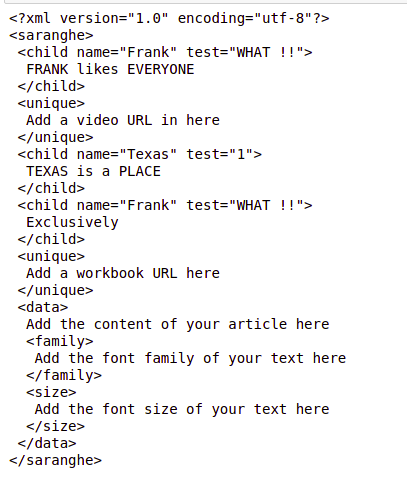
for tag in bs_data.find_all('child', {'name':'Frank'}):
tag['test'] = "WHAT !!"
# Output the contents of the
# modified xml file
print(bs_data.prettify())
Выход:
Использование Elementree
Модуль Elementree предоставляет нам множество инструментов для работы с XML-файлами. Лучшей частью этого является его включение во встроенную библиотеку стандартного Python. Поэтому для этого не нужно устанавливать какие-либо внешние модули. Поскольку xmlformat по своей сути является иерархическим форматом данных, его намного проще представить в виде дерева. Модуль предоставляет ElementTree предоставляет методы для представления всего XML-документа в виде единого дерева.
В последующих примерах мы рассмотрим дискретные методы чтения и записи данных в XML-файлы и из них.
Чтение XML-файлов
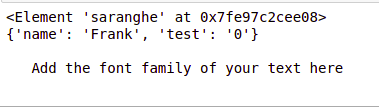
Чтобы прочитать XML-файл с помощью ElementTree, во-первых, мы импортируем класс ElementTree, найденный в библиотеке xml, под именем ET (общее соглашение). Затем передал имя файла xml в метод ElementTree.parse (), чтобы включить синтаксический анализ нашего xml-файла. Затем получил корневой (родительский тег) нашего xml-файла с помощью getroot(). Затем отображается (печатается) корневой тег нашего xml-файла (неявным способом). Затем отображаются атрибуты под тега нашего родительского тега с помощью root[0].attrib. root[0] для первого тега родительского корня и attrib для получения его атрибутов. Затем мы отобразили текст, заключенный в 1-м под теге 5-го под тега корневого тега.
Пример:
# importing element tree
# under the alias of ET
import xml.etree.ElementTree as ET
# Passing the path of the
# xml document to enable the
# parsing process
tree = ET.parse('dict.xml')
# getting the parent tag of
# the xml document
root = tree.getroot()
# printing the root (parent) tag
# of the xml document, along with
# its memory location
print(root)
# printing the attributes of the
# first tag from the parent
print(root[0].attrib)
# printing the text contained within
# first subtag of the 5th tag from
# the parent
print(root[5][0].text)
Выход:
Запись XML-файлов
Теперь мы рассмотрим некоторые методы, которые можно использовать для записи данных в xml-документ. В этом примере мы создадим xml-файл с нуля.
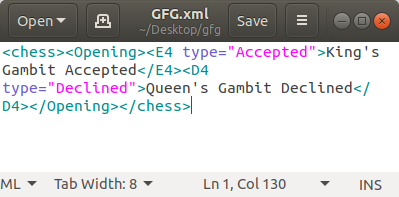
Для этого, во-первых, мы создаем корневой (родительский) тег под именем chess, используя команду ET.Элемент(‘шахматы»). Все теги будут располагаться под этим тегом, то есть, как только корневой тег будет определен, под ним могут быть созданы другие под элементы. Затем мы создали под тег/подэлемент с именем Открытие внутри шахматного тега, используя команду ET.ПодЭлемент(). Затем мы создали еще два под тега, которые находятся под открытием тега с именами E4 и D4. Затем мы добавили атрибуты к E4 и D4 теги с использованием set() , который является методом, найденным внутри SubElement (), который используется для определения атрибутов тега. Затем мы добавили текст между буквами E4 и D4 теги, использующие текст атрибута, найденный внутри функции подэлемента. В конце концов мы преобразовали тип данных содержимого, которое мы создавали, из ‘xml.etree. Элемент три. Объект «Элемент’ в байты, используя command ET.tostring() (даже если имя функции tostring() в некоторых реализациях преобразует тип данных в «байты», а не в «str»). Наконец, мы сбросили данные в файл с именем gameofsquares.xml который открыт в режиме «wb», чтобы разрешить запись в него двоичных данных. В конце концов, мы сохранили данные в наш файл.
Пример:
import xml.etree.ElementTree as ET
# This is the parent (root) tag
# onto which other tags would be
# created
data = ET.Element('chess')
# Adding a subtag named `Opening`
# inside our root tag
element1 = ET.SubElement(data, 'Opening')
# Adding subtags under the `Opening`
# subtag
s_elem1 = ET.SubElement(element1, 'E4')
s_elem2 = ET.SubElement(element1, 'D4')
# Adding attributes to the tags under
# `items`
s_elem1.set('type', 'Accepted')
s_elem2.set('type', 'Declined')
# Adding text between the `E4` and `D5`
# subtag
s_elem1.text = "King's Gambit Accepted"
s_elem2.text = "Queen's Gambit Declined"
# Converting the xml data to byte object,
# for allowing flushing data to file
# stream
b_xml = ET.tostring(data)
# Opening a file under the name `items2.xml`,
# with operation mode `wb` (write + binary)
with open("GFG.xml", "wb") as f:
f.write(b_xml)
Выход: