
Python — отличный язык для анализа данных, в первую очередь из-за фантастической экосистемы ориентированных на данные пакетов python. Pandas является одним из таких пакетов и значительно упрощает импорт и анализ данных.
Import Pandas:
import pandas as pdКод #1 :
read_csv это важная функция pandas для чтения csv-файлов и выполнения операций с ними.
# Import pandas
import pandas as pd
# reading csv file
pd.read_csv("filename.csv")
Открыть CSV-файл с помощью этого очень просто. Но есть много других вещей, которые можно сделать с помощью этой функции только для того, чтобы полностью изменить возвращаемый объект. Например, можно прочитать csv-файл не только локально, но и с URL-адреса через read_csv, или можно выбрать, какие столбцы необходимо экспортировать, чтобы нам не пришлось редактировать массив позже.
Вот список параметров, которые он принимает, со значениями по Default values.
pd.read_csv(filepath_or_buffer, sep=’, ‘, delimiter=None, header=’infer’, names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression=’infer’, thousands=None, decimal=b’.’, lineterminator=None, quotechar='”‘, quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, doublequote=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None) Не все из них очень важны, но запоминание их на самом деле экономит время на самостоятельном выполнении одних и тех же функций. Параметры любой функции можно просмотреть, нажав shift + tab в записной книжке jupyter. Полезные из них приведены ниже с их использованием :
| Параметр | Воспользуйся |
|---|---|
| filepath_or_buffer | URL или директория расположения файла |
| sep | Расшифровывается как разделитель, по умолчанию»,‘, как в csv(значения, разделенные запятыми) |
| index_col | Делает переданный столбец индексом вместо 0, 1, 2, 3…r |
| use_cols | Only uses the passed col[string list] to make data frame |
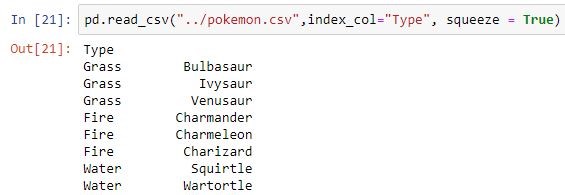
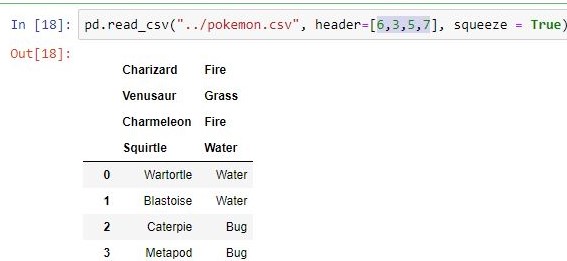
| squeeze | If true and only one column is passed, returns pandas series |
| skiprows | Skips passed rows in new data frame |
Обратитесь по ссылке к набору данных, используемому здесь.
Код #2 :
# importing Pandas library
import pandas as pd
pd.read_csv(filepath_or_buffer = "pokemon.csv")
# makes the passed rows header
pd.read_csv("pokemon.csv", header =[1, 2])
# make the passed column as index instead of 0, 1, 2, 3....
pd.read_csv("pokemon.csv", index_col ='Type')
# uses passed cols only for data frame
pd.read_csv("pokemon.csv", usecols =["Type"])
# returns pandas series if there is only one column
pd.read_csv("pokemon.csv", usecols =["Type"],
squeeze = True)
# skips the passed rows in new series
pd.read_csv("pokemon.csv",
skiprows = [1, 2, 3, 4])

