В этой статье объясняется, как загрузить и проанализировать CSV-файл на Python.
Прежде всего, что такое CSV-файл ?
CSV (значения, разделенные запятыми) — это простой формат файла, используемый для хранения табличных данных, таких как электронная таблица или база данных. Файл CSV хранит табличные данные (цифры и текст) в виде обычного текста. Каждая строка файла представляет собой запись данных. Каждая запись состоит из одного или нескольких полей, разделенных запятыми. Использование запятой в качестве разделителя полей является источником имени для этого формата файла.
Для работы с CSV-файлами в python существует встроенный модуль под названием csv.
Чтение CSV-файла
# importing csv module
import csv
# csv file name
filename = "aapl.csv"
# initializing the titles and rows list
fields = []
rows = []
# reading csv file
with open(filename, 'r') as csvfile:
# creating a csv reader object
csvreader = csv.reader(csvfile)
# extracting field names through first row
fields = next(csvreader)
# extracting each data row one by one
for row in csvreader:
rows.append(row)
# get total number of rows
print("Total no. of rows: %d"%(csvreader.line_num))
# printing the field names
print('Field names are:' + ', '.join(field for field in fields))
# printing first 5 rows
print('\nFirst 5 rows are:\n')
for row in rows[:5]:
# parsing each column of a row
for col in row:
print("%10s"%col),
print('\n')
Вывод вышеприведенной программы выглядит следующим образом:

В приведенном выше примере используется файл CSV aapl.csv, который можно загрузить отсюда.
Запустите эту программу с файлом aapl.csv в том же каталоге.
Давайте попробуем разобраться в этом фрагменте кода.
with open(filename, 'r') as csvfile:
csvreader = csv.reader(csvfile)Здесь мы сначала открываем CSV-файл в режиме ЧТЕНИЯ. Файловый объект называется как csv-файл. Объект file преобразуется в объект csv.reader. Мы сохраняем объект csv.reader как csvreader.
fields = csvreader.next()csvreader является повторяющимся объектом. Следовательно, метод .next() возвращает текущую строку и перемещает итератор в следующую строку. Поскольку первая строка нашего csv-файла содержит заголовки (или имена полей), мы сохраняем их в списке под названием поля.
for row in csvreader: rows.append(row)Теперь мы повторяем оставшиеся строки, используя цикл for. Каждая строка добавляется в список под названием строки. Если вы попытаетесь распечатать каждую строку, можно обнаружить, что эта строка представляет собой не что иное, как список, содержащий все значения полей.
print("Total no. of rows: %d"%(csvreader.line_num))csvreader.line_num это не что иное, как счетчик, который возвращает количество повторенных строк.
Запись в CSV-файл
# importing the csv module
import csv
# field names
fields = ['Name', 'Branch', 'Year', 'CGPA']
# data rows of csv file
rows = [ ['Nikhil', 'COE', '2', '9.0'],
['Sanchit', 'COE', '2', '9.1'],
['Aditya', 'IT', '2', '9.3'],
['Sagar', 'SE', '1', '9.5'],
['Prateek', 'MCE', '3', '7.8'],
['Sahil', 'EP', '2', '9.1']]
# name of csv file
filename = "university_records.csv"
# writing to csv file
with open(filename, 'w') as csvfile:
# creating a csv writer object
csvwriter = csv.writer(csvfile)
# writing the fields
csvwriter.writerow(fields)
# writing the data rows
csvwriter.writerows(rows)
Давайте попробуем разобраться в приведенном выше коде по частям.
fields (поля) и rows (строки) были уже определены. поля-это список, содержащий все имена полей. rows (строки) это список списков. Каждая строка представляет собой список, содержащий значения полей этой строки.
with open(filename, 'w') as csvfile: csvwriter = csv.writer(csvfile)Здесь мы сначала открываем CSV-файл в режиме ЗАПИСИ. Файловый объект называется как csv-файл. Объект file преобразуется в объект csv.writer. Мы сохраняем объект csv.writer как csvwriter.
csvwriter.writerow(fields)Теперь мы используем метод writerow для записи первой строки, которая представляет собой не что иное, как имена полей.
csvwriter.writerows(rows)Мы используем метод writerows для записи нескольких строк одновременно.
Запись словаря в файл CSV
# importing the csv module
import csv
# my data rows as dictionary objects
mydict =[{'branch': 'COE', 'cgpa': '9.0', 'name': 'Nikhil', 'year': '2'},
{'branch': 'COE', 'cgpa': '9.1', 'name': 'Sanchit', 'year': '2'},
{'branch': 'IT', 'cgpa': '9.3', 'name': 'Aditya', 'year': '2'},
{'branch': 'SE', 'cgpa': '9.5', 'name': 'Sagar', 'year': '1'},
{'branch': 'MCE', 'cgpa': '7.8', 'name': 'Prateek', 'year': '3'},
{'branch': 'EP', 'cgpa': '9.1', 'name': 'Sahil', 'year': '2'}]
# field names
fields = ['name', 'branch', 'year', 'cgpa']
# name of csv file
filename = "university_records.csv"
# writing to csv file
with open(filename, 'w') as csvfile:
# creating a csv dict writer object
writer = csv.DictWriter(csvfile, fieldnames = fields)
# writing headers (field names)
writer.writeheader()
# writing data rows
writer.writerows(mydict)
В этом примере мы пишем словарь mydict в файл CSV.
with open(filename, 'w') as csvfile: writer = csv.DictWriter(csvfile, fieldnames = fields)Здесь объект file (csvfile) преобразуется в объект диктанта.
Здесь мы указываем, что fieldnames в качестве аргумента.
writer.writeheader()метод writeheader просто записывает первую строку вашего csv-файла, используя предварительно указанные имена полей.
writer.writerows(mydict)- метод writerows просто записывает все строки, но в каждой строке он записывает только значения(не ключи).
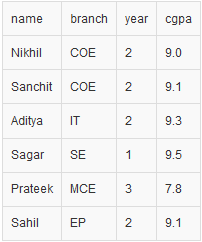
Итак, в конце концов, наш CSV-файл выглядит следующим образом:
Важные моменты:
- В модулях csv, может быть задан параметр диалекта, который используется для определения набора параметров, специфичных для конкретного Формат CSV. По умолчанию модуль csv использует диалект excel, который делает их совместимыми с электронными таблицами Excel. Вы можете определить свой собственный диалект, используя метод register_dialect.
Вот пример:
csv.register_dialect(
'mydialect',
delimiter = ',',
quotechar = '"',
doublequote = True,
skipinitialspace = True,
lineterminator = '\r\n',
quoting = csv.QUOTE_MINIMAL)Теперь, определяя объект csv.reader или csv.writer, мы можем указать диалект следующим образом
этот:
csvreader = csv.reader(csvfile, dialect='mydialect')- Теперь учтите, что CSV-файл выглядит так в обычном тексте:

Мы замечаем, что разделителем является не запятая, а точка с запятой. Кроме того, строки разделены двумя новыми строками вместо одной. В таких случаях мы можем указать разделитель и окончание строки следующим образом:
csvreader = csv.reader(csvfile, delimiter = ';', lineterminator = '\n\n')Итак, это было краткое, но краткое обсуждение того, как загружать и анализировать CSV-файлы в программе на python.