
DOM (объектная модель документа) — это кросс-языковой API от W3C, т. е. консорциума World Wide Web для доступа и изменения XML — документов. Python позволяет анализировать XML-файлы с помощью xml.dom.minidom, который является минимальной реализацией интерфейса DOM. Это проще, чем полный DOM API, и его следует рассматривать как меньший.
Шаги для анализа XML следующие:
- Импортируйте модуль
import xml.dom.minidomДопустим, ваши XML-файлы будут содержать следующие данные:
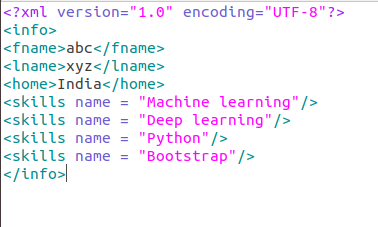
- Используйте функцию синтаксического анализа для загрузки и анализа XML-файла. В приведенном ниже случае в документах хранится результат функции синтаксического анализа
docs = xml.dom.minidom.parse("test.xml")- Давайте напечатаем имя дочернего тега и имя узла XML — файла.
import xml.dom.minidom
docs = xml.dom.minidom.parse("test.xml")
print(docs.nodeName)
print(docs.firstChild.tagName)
Выход:
#document info- Теперь, чтобы получить информацию из имени тега, вам нужно вызвать стандартную функцию dom getElementsByTagName и Атрибут getAttribute для получения необходимых атрибутов.
import xml.dom.minidom
docs = xml.dom.minidom.parse("test.xml")
print(docs.nodeName)
print(docs.firstChild.tagName)
skills = docs.getElementsByTagName("skills")
print("%d skills" % skills.length)
for i in skills:
print(i.getAttribute("name"))
Выход:
#document
info
4 skills
Machine learning
Deep learning
Python
Bootstrap