Расширяемый язык разметки (XML) — это язык разметки, который определяет набор правил для кодирования документов в формате, удобочитаемом как для человека, так и для машины.Цели разработки XML сосредоточены на простоте, универсальности и удобстве использования в Интернете.Это формат текстовых данных с сильной поддержкой через Юникод для различных человеческих языков. Хотя дизайн XML ориентирован на документы, этот язык широко используется для представления произвольных структур данных, таких как те, которые используются в веб-службах.
XML по своей сути является иерархическим форматом данных, и наиболее естественным способом его представления является дерево.Для выполнения любых операций, таких как синтаксический анализ, поиск, изменение XML-файла, мы используем модуль xml.etree.ElementTree. Он состоит из двух classes.ElementTree представляет весь XML — документ в виде дерева, которое помогает при выполнении операций. Element представляет собой один узел в этом дереве. Чтение и запись всего документа выполняются на уровне дерева элементов. Взаимодействие с одним XML-элементом и его под элементами осуществляется на уровне элементов.
| Свойства | Описание |
|---|---|
| Tag | Строка, определяющая, какие данные представляет элемент. Можно получить доступ с помощью имя элемента.тег. |
| Number of Attributes | Хранится в виде словаря python. Может быть доступ по имя элемента.attrib |
| Text string | Строковая информация об элементе. |
| Child string | Необязательные дочерние элементы строковой информации. |
| Child Elements | Количество дочерних элементов для определенного корня. |
Разбор:
Мы можем анализировать XML — данные из строки или XML-документа.Принимая во внимание xml.etree.ElementTree как и ET.
1. ET.parse(‘Filename’).getroot() — ET.parse(‘fname’) — создает дерево, а затем мы извлекаем корень с помощью .getroot().
2. ET.fromstring(stringname) — Чтобы создать корневой каталог из строки данных XML.
Пример 1:
XML-документ:
<?xml version="1.0"?>
<!--COUNTRIES is the root element-->
<COUNTRIES>
<country name="INDIA">
<neighbor name="Dubai" direction="W"/>
</country>
<country name="Singapore">
<neighbor name="Malaysia" direction="N"/>
</country>
</COUNTRIES>
Код на Python:
# importing the module.
import xml.etree.ElementTree as ET
XMLexample_stored_in_a_string ='''<?xml version ="1.0"?>
<COUNTRIES>
<country name ="INDIA">
<neighbor name ="Dubai" direction ="W"/>
</country>
<country name ="Singapore">
<neighbor name ="Malaysia" direction ="N"/>
</country>
</COUNTRIES>
'''
# parsing directly.
tree = ET.parse('xmldocument.xml')
root = tree.getroot()
# parsing using the string.
stringroot = ET.fromstring(XMLexample_stored_in_a_string)
# printing the root.
print(root)
print(stringroot)
Выход:

Методы элементов:
1) Element.iter(‘tag’) — Перебирает все дочерние элементы(элементы поддерева)
2) Element.findall(‘tag’) — Находит только элементы с тегом, которые являются прямыми дочерними элементами текущего элемента.
3) Element.find(‘tag’) — Находит первого ребенка с определенным тегом.
4) Element.get(‘tag’) — Доступ к атрибутам элементов.
5) Element.text — Дает текст элемента.
6) Element.attrib — возвращает все присутствующие атрибуты.
7) Element.tag — возвращает имя элемента.
Пример 2:
import xml.etree.ElementTree as ET
XMLexample_stored_in_a_string ='''<?xml version ="1.0"?>
<States>
<state name ="TELANGANA">
<rank>1</rank>
<neighbor name ="ANDHRA" language ="Telugu"/>
<neighbor name ="KARNATAKA" language ="Kannada"/>
</state>
<state name ="GUJARAT">
<rank>2</rank>
<neighbor name ="RAJASTHAN" direction ="N"/>
<neighbor name ="MADHYA PRADESH" direction ="E"/>
</state>
<state name ="KERALA">
<rank>3</rank>
<neighbor name ="TAMILNADU" direction ="S" language ="Tamil"/>
</state>
</States>
'''
# parsing from the string.
root = ET.fromstring(XMLexample_stored_in_a_string)
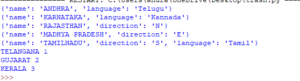
# printing attributes of the root tags 'neighbor'.
for neighbor in root.iter('neighbor'):
print(neighbor.attrib)
# finding the state tag and their child attributes.
for state in root.findall('state'):
rank = state.find('rank').text
name = state.get('name')
print(name, rank)
Выход:
ИЗМЕНЕНИЕ:
Изменение XML-документа также может быть выполнено с помощью методов элементов.
Методы:
1) Element.set(‘attrname’, ‘value’) – Изменение атрибутов элемента.
2) Element.SubElement(parent, new_childtag) — создает новый дочерний тег под родителем.
3) Element.write(‘filename.xml’) — создает дерево xml в другом файле.
4) Element.pop() — удалить определенный атрибут.
5) Element.remove() — для удаления полного тега.
Пример 3:
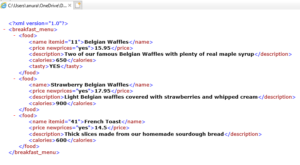
XML-документ:
<?xml version="1.0"?>
<breakfast_menu>
<food>
<name itemid="11">Belgian Waffles</name>
<price>5.95</price>
<description>Two of our famous Belgian Waffles
with plenty of real maple syrup</description>
<calories>650</calories>
</food>
<food>
<name itemid="21">Strawberry Belgian Waffles</name>
<price>7.95</price>
<description>Light Belgian waffles covered
with strawberries and whipped cream</description>
<calories>900</calories>
</food>
<food>
<name itemid="31">Berry-Berry Belgian Waffles</name>
<price>8.95</price>
<description>Light Belgian waffles covered with
an assortment of fresh berries and whipped cream</description>
<calories>900</calories>
</food>
<food>
<name itemid="41">French Toast</name>
<price>4.50</price>
<description>Thick slices made from our
homemade sourdough bread</description>
<calories>600</calories>
</food>
</breakfast_menu>
Код на Python:
import xml.etree.ElementTree as ET
mytree = ET.parse('xmldocument.xml.txt')
myroot = mytree.getroot()
# iterating through the price values.
for prices in myroot.iter('price'):
# updates the price value
prices.text = str(float(prices.text)+10)
# creates a new attribute
prices.set('newprices', 'yes')
# creating a new tag under the parent.
# myroot[0] here is the first food tag.
ET.SubElement(myroot[0], 'tasty')
for temp in myroot.iter('tasty'):
# giving the value as Yes.
temp.text = str('YES')
# deleting attributes in the xml.
# by using pop as attrib returns dictionary.
# removes the itemid attribute in the name tag of
# the second food tag.
myroot[1][0].attrib.pop('itemid')
# Removing the tag completely we use remove function.
# completely removes the third food tag.
myroot.remove(myroot[2])
mytree.write('output.xml')
Выход: