
response.iter_content() выполняет итерацию по response.content. Запросы Python обычно используются для извлечения содержимого из определенного URI ресурса. Всякий раз, когда мы делаем запрос к указанному URI через Python, он возвращает объект ответа. Теперь этот объект ответа будет использоваться для доступа к определенным функциям, таким как содержимое, заголовки и т.д. Эта статья посвящена тому, как проверить response.iter_content() из объекта ответа.
Как использовать response.iter_content() с помощью запросов Python?
Чтобы проиллюстрировать использование response.iter_content(), давайте пропингуем programbox.ru. Чтобы запустить этот скрипт, на вашем компьютере должны быть установлены Python и запросы.
Предпосылки:
- Скачайте и установите последнюю версию Python 3
- Как установить запросы на Python – для Windows, Linux, Mac
Пример кода:
# import requests module
import requests
# Making a get request
response = requests.get('https://programbox.ru')
# print response
print(response)
# print iter_content data
print(response.iter_content())
# iterates over the list
for i in response.iter_content():
print(i)
Пример реализации:
Сохраните указанный выше файл как request.py и запустите с помощью:
Python request.pyВыход:
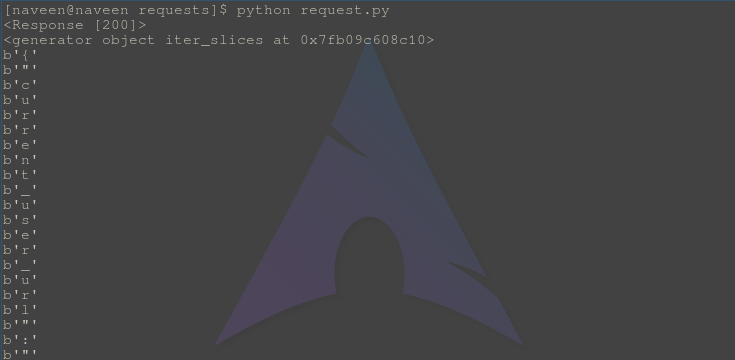
Проверьте, что объект итератора и итераторы в начале вывода отображаются объект итератора и элементы итерации в байтах соответственно.
Передовые Концепции
Существует множество библиотек для выполнения HTTP-запроса на Python, таких как httplib, urllib, httplib2, treq и т.д., Но запросы являются одними из лучших с интересными функциями. Если какой-либо атрибут запросов показывает значение NULL, проверьте код состояния, используя атрибут ниже.
requests.status_codeЕсли код состояния не находится в диапазоне 200-29. Вероятно, вам нужно проверить метод begin, используемый для отправки запроса + URL-адрес, который вы запрашиваете для ресурсов.
