

Существует несколько способов чтения файла строка за строкой с помощью Node.js. В Node.js файлы могут быть прочитаны синхронно или асинхронно. С помощью асинхронного пути можно читать большие файлы без загрузки всего содержимого файла в память.
Чтение всего файла сразу увеличит объем памяти процесса. Благодаря возможности загрузки и чтения файла строка за строкой это позволяет нам останавливать процесс на любом этапе в соответствии с потребностями. В этом посте мы рассмотрим 3 способа чтения файла строка за строкой с помощью Node.js с сравнением использования памяти.
Содержание
- Предпосылки
- Файл теста
- Синхронизация чтения файлов
- Прочитанная строка
- N-строки чтения
- Считыватель строк
- Другие варианты
- Быстрое сравнение
- Вывод
Предпосылки
Прежде чем перейти к коду, ниже приведены некоторые предварительные условия, которым необходимо следовать вместе с приведенными примерами кода:
- Имея Node.js Требуется 10+ (предпочтительно последний узел LTS 16), работающий на вашей машине/тестовой среде. Вы даже можете использовать Node.js на докера за это.
- Потребуются знания о том, как устанавливать модули NPM.
- Любое предварительное понимание потоков и того, как они работают, было бы полезно.
- Любые знания архитектуры узла, основанной на событиях, будут полезны.
Я запускаю код на компьютере Mac с Node.js 14. В следующем разделе мы рассмотрим файл, который мы собираемся использовать для чтения строки за строкой с Node.js. Примеры кода доступны в общедоступном репозитории GitHub для вашего удобства.
Файл теста
Для всех приведенных ниже маршрутов мы будем использовать файл дампа SQL объемом 90 МБ, который я взял из этого хранилища клонов BroadbandNow. Один и тот же файл используется для каждого метода чтения файла строка за строкой в Node.js чтобы обеспечить согласованность теста между различными методами. Мы также рассмотрим потребление памяти и время, необходимое для чтения файла размером 90 МБ, содержащего 798148 строк текста. Это должно быть хорошим тестом, чтобы посмотреть, как эти способы работают для относительно большого файла.
Синхронизация чтения файлов
Возможно, мы сможем прочитать файл синхронно, то есть загрузить весь файл размером 90 МБ в память и просмотреть его. Но, поскольку мы сначала загрузим весь файл, прежде чем читать из него какие-либо строки, потребление памяти, несомненно, составит более 90 МБ. Вот краткий пример для чтения файла строка за строкой, но не очень эффективным способом синхронизации:Копировать
const fs = require('fs');
const allFileContents = fs.readFileSync('broadband.sql', 'utf-8');
allFileContents.split(/\r?\n/).forEach(line => {
console.log(`Line from file: ${line}`);
});
const used = process.memoryUsage().heapUsed / 1024 / 1024;
console.log(`The script uses approximately ${Math.round(used * 100) / 100} MB`);Поскольку мы используем fs собственный модуль, нет необходимости устанавливать какой-либо новый модуль NPM. В приведенном выше коде мы синхронно читаем файл while, затем перебираем каждую строку по очереди и печатаем ее на консоль с помощью a console.log.
После завершения цикла мы распечатываем приблизительное использование памяти. Этот код можно найти в этом запросе на вытягивание для вашей справки. Если мы запустим этот скрипт с префиксом времени, как показано ниже:Копировать
node readfilesync.jsОн будет запущен и завершится выводом следующим образом:
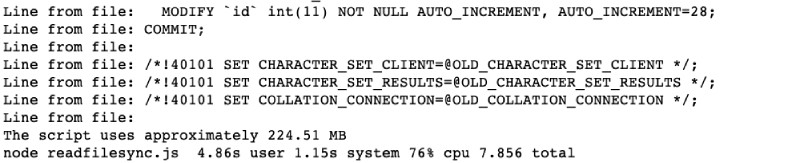
Как и ожидалось, для файла размером 90 МБ потребовалось ~225 МБ памяти и 7,85 секунды, чтобы он прошел через 798 тыс. строк текста.
Если есть файл объемом 1 ГБ, не рекомендуется использовать этот метод, так как при попытке загрузить весь файл в память у него закончится память.
Далее мы рассмотрим более эффективный асинхронный способ чтения файла построчно readline и потока, который является другим родным Node.js модуль.
С readline
Readline является родным Node.js модуль, поэтому для его использования нет необходимости устанавливать новый модуль NPM. Его можно использовать для чтения файлов строка за строкой, читая по одной строке за раз из любого читаемого потока. Мы будем использовать метод on с line событием, которое генерируется, когда входной поток получает ввод в конце строки \n, \r,или \r\n.
Ниже приведен пример кода readline с читаемым потоком:Копировать
const events = require('events');
const fs = require('fs');
const readline = require('readline');
(async function processLineByLine() {
try {
const rl = readline.createInterface({
input: fs.createReadStream('broadband.sql'),
crlfDelay: Infinity
});
rl.on('line', (line) => {
console.log(`Line from file: ${line}`);
});
await events.once(rl, 'close');
console.log('Reading file line by line with readline done.');
const used = process.memoryUsage().heapUsed / 1024 / 1024;
console.log(`The script uses approximately ${Math.round(used * 100) / 100} MB`);
} catch (err) {
console.error(err);
}
})();Давайте разберемся, что происходит в приведенном выше сценарии. Сначала нам потребуется 3 родных node.js модули события, fs и строка чтения. После этого мы определяем вызываемую асинхронную функцию processLineByLine, которая создает интерфейс для строки чтения, где вводом является строка чтения, в которую мы передаем наш тестовый файл размером 90 МБ. В соответствии с параметрами интерфейса создания, параметр crlfDelay, установленный на бесконечность, будет рассматриваться \r\n как одна новая строка.
Поскольку мы взаимодействуем с читаемым потоком, при каждом событии чтения строки он будет вызывать ri.on функцию с этим line событием. В этот момент мы регистрируем содержимое строки, прочитанной из потока. Затем мы прослушиваем событие readline close events.once, которое создает обещание, которое будет разрешено с помощью массива всех аргументов, переданных данному событию. В этом случае это будет пустой массив.
Наконец, мы считываем данные об использовании памяти и регистрируем их. Вы можете сослаться на приведенный выше код в этом запросе на извлечение. Когда мы запускаем этот сценарий с:Копировать
node readline.jsЭто дает следующий результат:

Как видно выше, модулю readline с читаемым потоком потребовалось всего 6,33 МБ памяти для чтения файла размером 90 МБ.
Как это было передано в потоковом режиме, что намного меньше, чем 225 МБ в предыдущем примере синхронизации.
Он завершил процесс за 7,365 секунды. Далее мы рассмотрим модуль NPM N-readlines для чтения файла построчно.
N-строк чтения
N-readline — это модуль NPM, который будет считывать файл строка за строкой без буферизации всего файла в памяти. Он делает это без использования потоков, считывая содержимое файла по частям с помощью буфера и модуля собственной файловой системы. Несмотря на то, что он работает синхронно, он не загружает весь файл в память.
Ниже приведен пример того, как использовать N-readline для чтения файла строка за строкой после его установки с npm i --save n-readlines
const nReadlines = require('n-readlines');
const broadbandLines = new nReadlines('broadband.sql');
let line;
let lineNumber = 1;
while (line = broadbandLines.next()) {
console.log(`Line ${lineNumber} has: ${line.toString('ascii')}`);
lineNumber++;
}
console.log('end of file.');
const used = process.memoryUsage().heapUsed / 1024 / 1024;
console.log(`The script uses approximately ${Math.round(used * 100) / 100} MB`);В приведенном выше коде, во-первых, нам требуется n-readlines модуль, и мы создаем его экземпляр с помощью нашего broadband.sql файла размером 90 Мбайт. Другие параметры, такие как readChunk и newLineCharacter могут быть переданы в качестве второго параметра, new nReadlines но мы используем значение по умолчанию.
Следовательно, мы определяем две переменные line и lineNumber. Переменная Line будет содержать строку для каждой строки файла, и в lineNumber ней будет содержаться номер строки от 1 до количества строк в файле.
Впоследствии мы перебираем строки, пока в файле есть строки с broadbankLines.next() вызовом. Поскольку он возвращает буфер, если строка существует, мы консольно регистрируем ее в CLI после преобразования в строку ASCII. Затем мы увеличиваем номер строки внутри цикла.
Наконец, мы печатаем end of file и, как и в приведенных выше примерах, также выводим приблизительное использование памяти. Этот код также доступен в качестве запроса на получение для вашей справки. Мы можем выполнить приведенный выше сценарий с помощью:Копировать
node n-readlines.jsК концу выполнения скрипта он выдаст следующий вывод:

Как видно выше, он выполнил задачу за 8,9 секунды.
Для печати всех 798 Тыс. строк SQL-файла объемом 90 МБ n-readlines потребляло всего 4,11 МБ памяти, что удивительно.
В следующем разделе мы увидим, как модуль NPM для чтения строк можно использовать для чтения файлов построчно с помощью Node.js.
Считыватель строк
Модуль NPM для чтения строк определяет себя как “Асинхронный, буферизованный, строчный считыватель файлов/потоков с поддержкой определяемых пользователем разделителей строк”. на своей странице GitHub. В разделе «Использование» страницы также упоминается, что eachLine функция считывает каждую строку данного файла. last Переменную в обратном вызове можно использовать для определения того, была ли достигнута последняя строка файла.
Ниже приведен рабочий пример чтения нашего относительно большого файла SQL размером 90 МБ с помощью программы чтения строк, мы установили его с npm i --save line-reader помощью, а затем создали следующий файл:Копировать
const lineReader = require('line-reader');
lineReader.eachLine('broadband.sql', function(line, last) {
console.log(`Line from file: ${line}`);
if(last) {
console.log('Last line printed.');
const used = process.memoryUsage().heapUsed / 1024 / 1024;
console.log(`The script uses approximately ${Math.round(used * 100) / 100} MB`);
}
});Сначала нам требуется модуль чтения строк, затем вызывается eachLine функция, передающая имя файла (или путь к файлу) в качестве первого параметра. Второй параметр-это функция обратного вызова, которая содержит строку и последние переменные. Впоследствии мы регистрируем строку из файла, доступного в переменной строки.
Далее, если мы обнаружим, что последняя переменная имеет значение true, что указывает на то, что мы достигли конца файла, мы регистрируем Last line printed сообщение, а также распечатываем приблизительную память, используемую для чтения файла строка за строкой. Этот код также доступен в качестве запроса на получение для вашей справки.
Мы можем запустить этот код, выполнив:Копировать
node line-reader.jsЭто закончится выводом, который выглядит следующим образом:

Как видно выше, сценарий был завершен за 10,66 секунды.
По сравнению с 225 МБ используемой памяти
fs.readFileSync, чтение файла объемом 90 МБ с помощью считывателя строк заняло всего 5,18 МБ памяти, что в 45 раз меньше.
Если вы хотите перезапустить свой Node.js скрипт при каждом изменении пробуйте Nodemon. Далее мы посмотрим, есть ли другие варианты, но мы наверняка рассмотрели топ-3 самых популярных.
Другие варианты
Существуют и другие варианты чтения файла строка за строкой с помощью Node.js. Существует очень популярный модуль NPM под названием readline, но из-за столкновения имени с собственным Node.js модуль, теперь он переименован в Строку за строкой. Он работает очень похоже на собственный модуль readline.
Другими менее популярными, но доступными вариантами являются строка чтения файла и строки чтения-ng. Оба они являются модулями NPM, но на прошлой неделе они загружались примерно 3 раза.
Для дальнейшей обработки содержимого файла было бы очень полезно использовать эти функции массива JavaScript. Это приведет нас к быстрому сравнению этих доступных вариантов.
Быстрое сравнение
Быстрое сравнение этих четырех модулей NPM с тенденциями NPM показало, что N-readlines является самым загружаемым из них с 56 тыс. загрузок за последнюю неделю. Второй-считыватель строк с 46 тысячами загрузок на прошлой неделе, но имейте в виду, что последний раз считыватель строк обновлялся 6 лет назад. Ниже приведен снимок загрузок за последний 1 год:
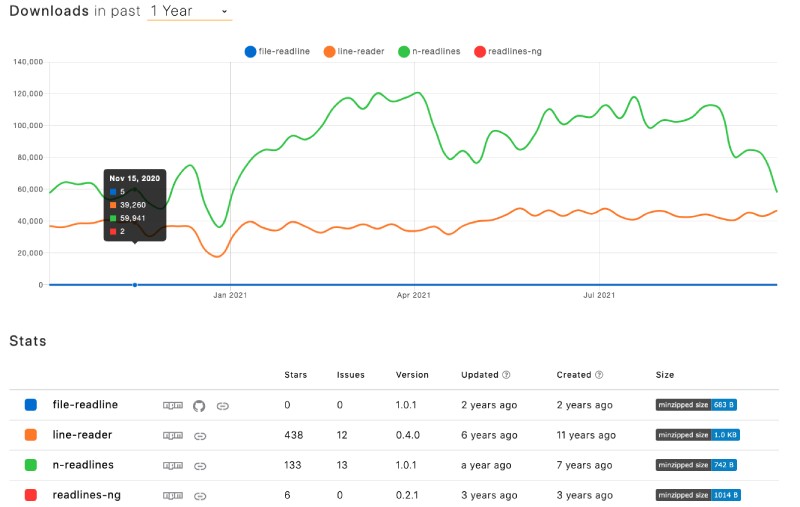
Лучше будет выбрать самые популярные, и последнее обновление-это n-readlines, которое было год назад.
Загрузка как для чтения строки файла, так и для чтения строк ng составляет около 3 в неделю по сравнению с 46 тыс. и 56 тыс. для чтения строк и n-строк соответственно.
Сделайте осознанный выбор для лучшей поддержки, если она вам нужна.
С точки зрения использования памяти и процессора все методы , за исключением первого fs.readfilesync, все остальные параметры на основе потока или обратного вызова, потребляют менее 10 МБ или памяти и завершаются до 10 секунд с использованием процессора 70-94%. Синхронизация чтения файлов потребляла 225 МБ памяти для файла размером 90 МБ.
Вывод
Мы рассмотрели, как читать файл строка за строкой в Node.js. Несмотря на то, что это кажется тривиальной проблемой, существует несколько способов сделать это в Node.js как и большинство вещей в JavaScript.
Мы также проанализировали использование памяти и время, которое потребовалось для каждого из 3 методов.
Наконец, мы рассмотрели краткое сравнение этих и других доступных вариантов с точки зрения популярности. Я надеюсь, что это поможет вам принять обоснованное решение читать файл строка за строкой с Node.js.
