
Craping веб-страниц — это процесс автоматического извлечения данных с веб-сайта и Node.js может использоваться для соскабливания паутины. Несмотря на то, что другие языки и фреймворки более популярны для веб-очистки, Node.js может быть также хорошо использован для выполнения этой работы. В этом посте мы узнаем, как выполнять craping веб-страниц с помощью Node.js для веб-сайтов, которые не нуждаются и нуждаются в загрузке Javascript. Давайте начнем!
Содержание
- Веб-выскабливание того, что можно и чего нельзя
- Предпосылки
- Соскабливание паутины с Node.js простой пример
- Node.js веб-очистка рендеринга JavaScript
- Вывод
Веб-выскабливание того, что можно и чего нельзя
Craping веб-страниц может быть очень полезной для сбора данных из нескольких источников или даже для отслеживания того, что делает конкурент. Но у него может быть свой собственный Юридическая информация и технические проблемы тоже. Общая техническая проблема заключается в том, что слишком много запросов поступает с одного и того же IP-адреса за очень короткий промежуток времени, поскольку трафик поступает с компьютера, а не с браузера или человека.
Даже при craping веб-сайта лучше всего уважайте robots.txt файл и будьте добры к сопровождающим веб-сайта. Не будьте тем человеком, который будет отправлять 50 запросов в секунду на веб-сайт с одного и того же IP-адреса, добавляя ненужную нагрузку на серверы и замедляя работу веб-сайта для других пользователей. Далее мы рассмотрим пример простого веб-скребка с Node.js.
Фреймворк Python Scrapy может быть одним из лучших инструментов для очистки веб-страниц, но если вы просто знаете Javascript, вы можете создать довольно приличный веб-скребок с помощью Node.js тоже.
Предпосылки
Прежде чем мы погрузимся в код, ниже приведены некоторые предварительные условия
- У вас есть Node.js (предпочтительно последняя версия LTS) и узел NPM, запущенный на вашем компьютере
- Установка модулей NPM вам известна
- Любые предварительные знания или опыт веб-очистки, селекторов CSS или Xpath будут полезны.
Давайте начнем с некоторого кода прямо сейчас.
Соскабливание паутины с Node.js простой пример
Веб-сайты и веб-страницы в основном можно разделить на две широкие категории. Первый сегмент не нуждается в рендеринге JavaScript для отображения большей части содержимого веб-страницы, а второму требуется выполнение Javascript для рендеринга любого его содержимого. Первую группу веб — сайтов гораздо легче очистить, потому что отображаемый HTML-код почти одинаков для браузера, который может выполнять Javascript, по сравнению с ботом, который не может выполнять JavaScript.
Второй набор веб-сайтов-это в основном одностраничные приложения (SPA), созданные с помощью JavaScript-фреймворка/библиотек, таких как React, которым требуется выполнение JavaScript для отображения любого соответствующего контента. Ниже мы рассмотрим пример для этого класса веб-сайтов. На данный момент мы рассмотрим пример, который не требует выполнения Javascript для получения содержательного содержимого веб-сайта. Для этого простого примера мы будем использовать Axios и Cheerio, чтобы очистить веб-сайт со списком недвижимости под названием Domain.com, чтобы проверить, сколько объектов аренды указано для данного почтового индекса.
Аксиос и Чирио за Node.js соскабливание паутины
Перед написанием некоторого кода, чтобы очистить информацию. Лучше всего проанализировать некоторые закономерности, которые облегчат нашу работу. При очистке контента необходимо учитывать две основные вещи: URL-адрес и структуру страниц, с которых вы хотите удалить информацию. URL-адреса имеют паттен, в нашем примере, если вы ищете арендуемую недвижимость в домене, URL-адрес с почтовым индексом выглядит так: https://www.domain.com.au/rent/?postcode=2000&excludedeposittaken=1 таким образом, 2000-это часть почтового индекса, которую можно изменить на любой действительный почтовый индекс в Австралии, и она будет работать.
Аналогично, когда мы просматриваем страницу и ищем нужную нам часть, это номер свойств в этом почтовом индексе. Он доступен в теге “сильный” внутри тега “h1”. Это легко увидеть в инспекторе выбранного вами браузера, я использую chrome ниже:
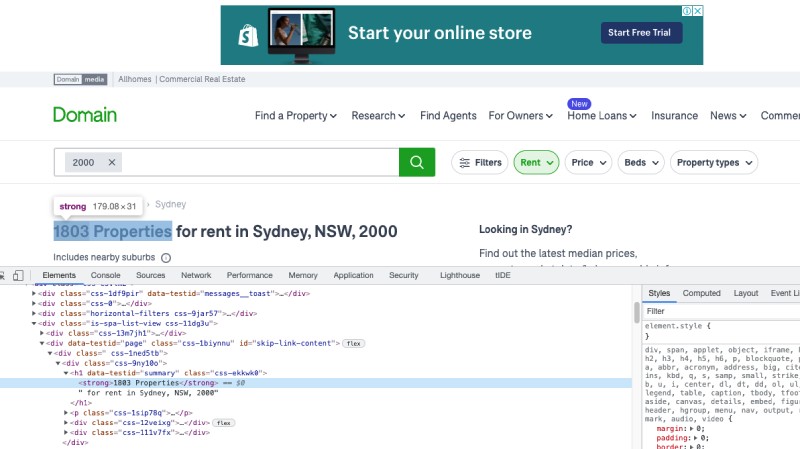
Здесь CSS-селекторы-ваш лучший друг, XPATH-еще один мощный вариант, но в целом я предпочитаю CSS-селекторы. Ниже приведен краткий обзор свойства внутреннего текста ‘h1>strong’, которое выдает текст, который нам нужен:
Теперь, когда мы знаем, на что ориентироваться на веб-странице, ниже приведен краткий пример получения количества объектов, открытых для аренды в данном почтовом индексе Австралии, из Domain.com.au страница списка аренды с использованием Axios и Cheerio.
const axios = require('axios');
const cheerio = require('cheerio');
(async () => {
const args = process.argv.slice(2);
const postCode = args[0] || 2000;
const url = `https://www.domain.com.au/rent/?postcode=${postCode}&excludedeposittaken=1`;
try {
const response = await axios.get(url);
const $ = cheerio.load(response.data);
const noOfProperties = $('h1>strong').text();
console.log(`${noOfProperties} are open for rent in ${postCode} postcode of Australia on Domain`);
} catch (e) {
console.error(`Error while fetching rental properties for ${postCode} - ${e.message}`);
}
})();Вы можете установить axios и cheerio с npm i --save axios cheerio любым Node.js проект, начатый с npm install -y.
В приведенном выше коде сначала нам требуются как Axios, так и Cheerio, а затем мы создаем асинхронный IIFE (Немедленно вызываемое функциональное выражение), поскольку мы хотели бы использовать внутри него await. Учитывая, что он немедленно вызывается, нам не нужно явно вызывать функцию.
Внутри функции мы получаем аргументы из командной строки, если таковые имеются. Затем мы устанавливаем в postCode качестве третьего аргумента команды , как node axios-cheerio.js 2100 в приведенном выше коде, значение postCode будет равно 2100.
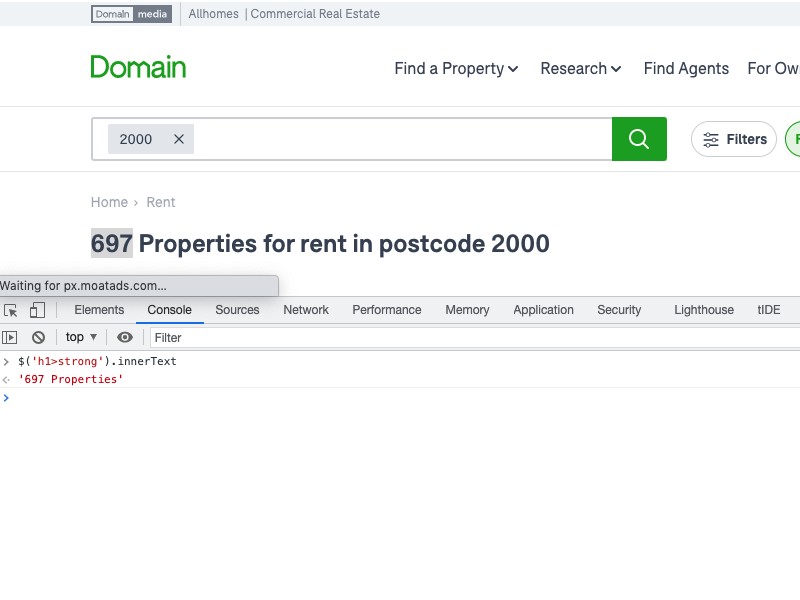
Впоследствии мы установили URL-адрес в качестве URL-адреса домена для поиска объектов аренды в данном почтовом индексе. После этого мы вызываем URL-адрес, чтобы получить его HTML с помощью Axios, мы выполняем ожидание, чтобы развернуть обещание. Как только мы получим ответ, мы передадим его в cheerio с загрузкой cheerio, чтобы проанализировать тело ответа. Следовательно, поскольку у нас есть полный HTML, мы используем простой API-интерфейс Cheerio, подобный Jquery, для анализа текста для сильного HTML-тега внутри тега H1, который имеет значение, подобное 217 properties. Затем, наконец, мы распечатываем сообщение и добавляем дополнительные строки для отображения вывода на консоли.
В случае какой-либо ошибки мы просто регистрируем сообщение об ошибке. Сценарий при запуске с node axios-cheerio.js 2100 дает следующий вывод:

Отлично работает наш базовый скребок с Axios и Cheerio. Приведенный выше код доступен в запросе на извлечение. Если вам нужен метод быстрого доступа, я тоже создал Axrio, который используется в проекте скребка домена, который я написал в 2018 году.
Axios и Cheerio-это всего лишь одна из комбинаций, которые вы можете использовать. Вместо Axios вы можете использовать другие библиотеки, такие как Got, Superagent и тому подобные. Вместо Cheerio вы также можете попробовать JsDOM. Главное-получить HTML и проанализировать его, чтобы извлечь из HTML необходимую нам информацию.
Далее мы рассмотрим, как очистить веб-страницы, для которых требуется JavaScript для отображения любого значимого контента для наших Node.js учебник по веб-очистке.
Node.js веб-очистка рендеринга JavaScript
Домен был относительно простым веб-сайтом, так как он отображает полный HTML-код с помощью рендеринга на стороне сервера. Теперь, если мы используем Axios и Cheerio, чтобы соскрести названия должностей со страницы списка вакансий Workable, он ничего не найдет. Поскольку страница не выполняет никаких заданий до тех пор, пока JavaScript на странице не запустится, не вызовет соответствующий API и не нарисует ответ из API.
Этим типам одностраничных приложений (SPA) потребуется реальный или безголовый браузер, чтобы выполнить JavaScript на странице и передать HTML в скребок, как если бы он работал для браузера. Давайте используем Puppeteer, чтобы соскрести названия должностей со страницы рабочих мест Workable.
Кукольник — это библиотека узлов, которая предоставляет API высокого уровня для управления Chrome или Chromium. По умолчанию он работает без головы (без графического интерфейса), но также может работать в режиме полного графического интерфейса. Его можно использовать для многих других целей, помимо простого рендеринга JavaScript, чтобы помочь в очистке. Его можно использовать для создания скриншотов или PDF-файлов, заполнения форм, использования для автоматического тестирования и т.д. Говоря о тестировании, существует только два типа автоматических тестов-быстрые и не быстрые.
Кукольник для соскабливания паутины
Чтобы использовать Puppeteer, мы можем установить его с npm i --save puppeteer помощью , он также загрузит последнюю версию chromium. Если вы хотите использовать свой собственный браузер, вы можете попробовать puppeteer-core. В этом руководстве мы будем использовать кукловода, чтобы все было просто.
Чтобы craping названия должностей на первой странице выполнимых, мы будем использовать следующий код.
const puppeteer = require('puppeteer');
(async () => {
try {
const browser = await puppeteer.launch();
const page = await browser.newPage();
const navigationPromise = page.waitForNavigation();
await page.goto('https://jobs.workable.com/');
await page.setViewport({ width: 1440, height: 744 });
await navigationPromise;
await page.waitForSelector('ul li h3 a');
let jobTitles = await page.$$eval('ul li h3 a', titles => {
return titles.map(title => title.innerText);
});
console.log(`Job Titles on first page of Workable are: ${jobTitles.join(', ')}`);
await browser.close();
} catch (e) {
console.log(`Error while fetching workable job titles ${e.message}`);
}
})();Код был частично сгенерирован с помощью плагина Google Chrome для записи без головы, вы также можете просмотреть его код на GitHub, если вам интересно.
Код сначала включает в себя кукловода. Затем в асинхронной функции IIFE, аналогичной приведенному выше примеру, запустите браузер и откройте новую вкладку. После этого он переходит к https://jobs.workable.com окну просмотра и устанавливает его. Следовательно, он ожидает перехода к и ждет селектора ul li h3 a. Затем он вводит все a теги ul li h3, все 10 из них, и перебирает их, чтобы получить внутренний текст, содержащий названия должностей. Который задан в jobTitles массиве. После этого он регистрирует все удаленные названия должностей, а затем закрывает браузер. Мы также можем использовать другие Node.js библиотеки ведения журнала вместо console.log.
Вот как это выглядит, когда вы запускаете его:

Если код запускается с помощью docker, для запуска браузера потребуется другой способ. В приведенном выше примере я запускаю его на компьютере Mac. Приведенный выше код доступен в качестве запроса на получение для вашей справки. Мы могли бы, возможно, взять весь HTML, отображаемый после выполнения JavaScript, и поместить его в Cheerio для его анализа, но описанный выше метод тоже работает.
Весь рабочий код доступен в качестве репозитория Github для вашей справки. Мы также можем использовать Node.js с помощью Docker можно легко запускать код в нескольких операционных системах и средах.
В дополнение к очистке только одной страницы мы могли бы получить все ссылки и просмотреть (или даже лучше пообещать.все) страницы, но в этот момент это был бы полноценный паук, а не просто очистка веб-страницы.
Еще одна альтернатива Кукловоду-Драматург. Он похож на puppeteer и имеет аналогичный API, преимущество в том, что он поддерживает несколько браузеров, таких как Firefox и Safari. Кроме того, вы также можете использовать другие языки, такие как Python, Java и .Net, а не только javascript. Плагин headless recorder может создать хороший начальный сценарий как для Кукольника, так и для драматурга, так что вы можете получить очень хорошую отправную точку, если вы не очень хорошо разбираетесь в написании таких сценариев автоматизации.
Вывод
Мы видели, как очищать веб-страницы с помощью Node.js для обоих типов веб-страниц, для которых не требуется JavaScipt для отображения значимого HTML и для которых требуется JavaScript. Использование инструмента проверки вашего браузера и некоторого сопоставления шаблонов URL-адресов, несомненно, поможет вам намного лучше обрабатывать веб-страницы.
