Не всегда возможно получить набор данных в формате CSV. Таким образом, Pandas предоставляет нам функции для преобразования наборов данных в других форматах в фрейм данных. Файл excel имеет формат ‘xlsx.
Прежде чем мы начнем, нам нужно установить несколько библиотек.
pip install pandas
pip install xlrdДля импорта файла Excel в Python с помощью Панд мы должны использовать pandas.read_excel().
Синтаксис: pandas.read_excel(io, sheet_name=0, header=0, names=None,….)
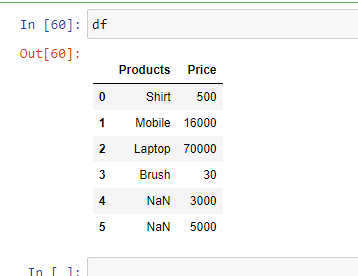
Возврат: DataFrame or dict of DataFrames.Предположим, файл Excel выглядит следующим образом:
Теперь мы можем погрузиться в код.
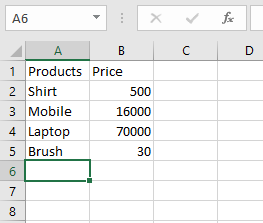
Пример 1: Прочитайте файл Excel.
import pandas as pd
df = pd.read_excel("sample.xlsx")
print(df)
Выход:
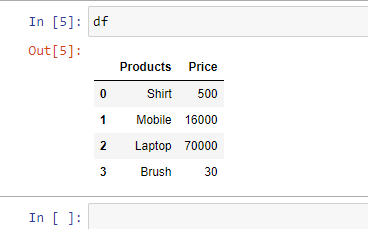
Пример 2: Чтобы выбрать определенный столбец, мы можем передать параметр “index_col“.
import pandas as pd
# Here 0th column will be extracted
df = pd.read_excel("sample.xlsx",
index_col = 0)
print(df)
Выход:
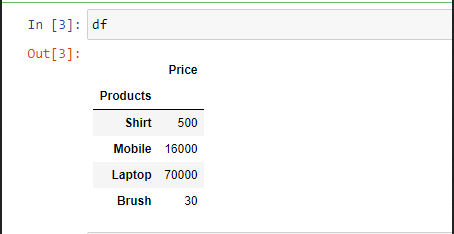
Пример 3. В случае, если вам не нравится начальный заголовок столбцов, вы можете изменить его на индексы, используя параметр “заголовок”.
import pandas as pd
df = pd.read_excel('sample.xlsx',
header = None)
print(df)
Выход:
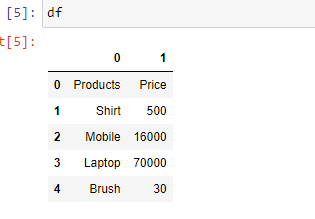
Пример 4. Если вы хотите изменить тип данных определенного столбца, вы можете сделать это с помощью параметра “dtype“.
import pandas as pd
df = pd.read_excel('sample.xlsx',
dtype = {"Products": str,
"Price":float})
print(df)
Выход:
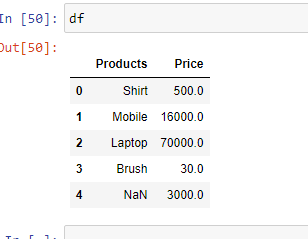
Пример 5: Если у вас есть неизвестные значения, то вы можете обработать их с помощью параметра “na_values«. Он преобразует упомянутые неизвестные значения в “NaN”.
import pandas as pd
df = pd.read_excel('sample.xlsx',
na_values =['item1',
'item2'])
print(df)
Выход: