
Лист Excel — одна из самых распространенных форм файлов в ИТ-индустрии. Все, кто в то или иное время пользовался компьютером, сталкивались с электронными таблицами Excel и работали с ними. Такая популярность excel обусловлена его широким спектром приложений в области хранения и обработки данных в табличной и систематизированной форме. Кроме того, листы Excel очень интуитивно понятны и удобны в использовании, что делает их идеальными для работы с большими наборами данных даже для менее технических специалистов. Если вы ищете места, где можно научиться манипулировать и автоматизировать файлы Excel с помощью Python, не ищите больше. Вы находитесь в нужном месте.
В этой статье вы узнаете, как использовать Pandas для работы с электронными таблицами Excel. В конце статьи вы получите знания of:
- Необходимые для этого модули и как их настроить в вашей системе.
- Чтение данных из файла Excel в панды с помощью Python.
- Изучение данных из файлов Excel в Панд.
- Использование функций для управления и изменения формы данных в Панд.
Установка
Чтобы установить pandas в Anaconda, мы можем использовать следующую команду в терминале Anaconda:
conda install pandasЧтобы установить pandas на обычный Python (не Anaconda), мы можем использовать следующую команду в командной строке:
pip install pandas Приступая к работе
Прежде всего, нам нужно импортировать модуль pandas, что можно сделать, выполнив команду:
import pandas as pds
Входной файл: Предположим, файл excel выглядит следующим образом
Лист 1:

Лист 2:

Теперь мы можем импортировать файл excel с помощью функции read_excel в pandas, как показано ниже:
file =('path_of_excel_file')
newData = pds.read_excel(file)
newData
Выход:
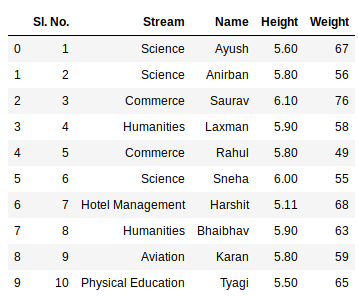
Второй оператор считывает данные из excel и сохраняет их в фрейме данных pandas, который представлен переменной newData. Если в книге Excel несколько листов, команда импортирует данные первого листа. Чтобы создать фрейм данных со всеми листами в книге, самый простой способ-создать разные фреймы данных отдельно, а затем объединить их. Метод read_excel принимает аргумент sheet_name и index_col где мы можем указать лист, из которого должен быть сделан фрейм данных, и index_col указывает столбец заголовка.
Пример:
sheet1 = pds.read_excel(file,
sheet_name = 0,
index_col = 0)
sheet2 = pds.read_excel(file,
sheet_name = 1,
index_col = 0)
newData = pds.concat([sheet1, sheet2])
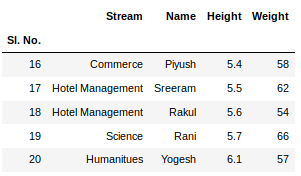
Третье утверждение объединяет оба листа. Теперь, чтобы проверить весь фрейм данных, мы можем просто выполнить следующую команду:
newData
Выход:

Чтобы просмотреть 5 столбцов сверху и снизу фрейма данных, мы можем выполнить команду:
newData.head()
newData.tail()
Выход:

Это head() и tail() метод также принимают аргументы в качестве чисел для отображения количества столбцов.
Этот shape() метод можно использовать для просмотра количества строк и столбцов во фрейме данных следующим образом:
newData.shape
Выход:

Если какой-либо столбец содержит числовые данные, мы можем отсортировать этот столбец с помощью sort_values() метода в pandas следующим образом:
sorted_column = newData.sort_values(['Height'], ascending = False)
Теперь предположим, что нам нужны 5 лучших значений отсортированного столбца, мы можем использовать head() метод здесь:
sorted_column['Height'].head(5)
Выход:

Мы можем сделать это с любым числовым столбцом фрейма данных, как показано ниже:
newData['Weight'].head()
Выход:

Теперь предположим, что наши данные в основном числовые. Мы можем получить статистическую информацию, такую как среднее, максимальное, минимальное и т. д., О фрейме данных, Используя метод, как показано ниже: describe()
newData.describe()
Выход:

Это также можно сделать отдельно для всех числовых столбцов, используя следующую команду:
newData['Weight'].mean()
Выход:

Другая статистическая информация также может быть рассчитана с использованием соответствующих методов.
Как и в Excel, формулы также могут быть применены, а вычисляемые столбцы могут быть созданы следующим образом:
newData['calculated_column']= newData[“Height”] + newData[“Weight”]
newData['calculated_column'].head()
Выход:

После обработки данных во фрейме данных мы можем экспортировать данные обратно в файл Excel с помощью этого метода to_excel. Для этого нам нужно указать выходной файл excel, в который должны быть записаны преобразованные данные, как показано ниже:
newData.to_excel('Output File.xlsx')
Выход:


