Анализ содержания книги / документа
Шаблоны в письменном тексте не одинаковы для всех авторов или языков. Это позволяет лингвистам изучать язык происхождения или потенциальное авторство текстов, где эти характеристики непосредственно не известны, например, федералистские документы Американской революции.
Цель: В этом тематическом исследовании мы рассмотрим свойства отдельных книг в коллекции книг разных авторов и на разных языках. Более конкретно, мы рассмотрим длину книги, количество уникальных слов и то, как эти атрибуты группируются по языку или авторству.
Источник: Проект «Гутенберг» — старейшая электронная библиотека книг. Он направлен на оцифровку и архивирование произведений культуры и в настоящее время содержит более 50 000 книг, все ранее опубликованные и теперь доступные в электронном виде. Загрузите некоторые из этих книг на английском и французском языках отсюда, а также книги на португальском и немецком языках отсюда для анализа. Поместите все эти книги вместе в папку под названием Книги с вложенными папками на английском, французском, немецком и потугском языках.
Частота слов в тексте
Поэтому мы собираемся создать функцию, которая будет подсчитывать частоту слов в тексте. Мы рассмотрим образец тестового текста, а позже заменим образец текста текстовым файлом книг, которые мы только что загрузили. Поскольку мы собираемся подсчитать частоту слов, следовательно, прописные и строчные буквы одинаковы. Мы преобразуем весь текст в нижний регистр и сохраним его.
text = "This is my test text. We're keeping this text short to keep things manageable."
text = text.lower()
Частоту слов можно подсчитать различными способами. Мы собираемся кодировать двумя такими способами ( просто для получения знаний ). Один использует цикл for, а другой использует счетчик из коллекций, который оказывается быстрее предыдущего. Функция вернет словарь уникальных слов и его частоту в виде пары ключ-значение. Итак, мы кодируем:
from collections import Counter
# counts word frequency
def count_words(text):
skips = [".", ", ", ":", ";", "'", '"']
for ch in skips:
text = text.replace(ch, "")
word_counts = {}
for word in text.split(" "):
if word in word_counts:
word_counts[word]+= 1
else:
word_counts[word]= 1
return word_counts
# >>>count_words(text) You can check the function
# counts word frequency using
# Counter from collections
def count_words_fast(text):
text = text.lower()
skips = [".", ", ", ":", ";", "'", '"']
for ch in skips:
text = text.replace(ch, "")
word_counts = Counter(text.split(" "))
return word_counts
# >>>count_words_fast(text) You can check the function
Вывод:
Вывод представляет собой словарь, содержащий уникальные слова образца текста в качестве ключа и частоту каждого слова в качестве значения. Сравнивая выходные данные обеих функций, мы имеем:
{‘were’: 1, ‘is’: 1, ‘manageable’: 1, ‘to’: 1, ‘things’: 1, ‘keeping’: 1, ‘my’: 1, ‘test’: 1, ‘text’: 2, ‘keep’: 1, ‘short’: 1, ‘this’: 2}
Counter({‘text’: 2, ‘this’: 2, ‘were’: 1, ‘is’: 1, ‘manageable’: 1, ‘to’: 1, ‘things’: 1, ‘keeping’: 1, ‘my’: 1, ‘test’: 1, ‘keep’: 1, ‘short’: 1})Чтение книг на Python: С тех пор мы успешно протестировали наши функции частоты слов с помощью образца текста. Теперь мы собираемся протестировать функции с книгами, которые мы загрузили в виде текстового файла. Мы собираемся создать функцию под названием read_book (), которая будет читать наши книги на Python, сохранять их в виде длинной строки в переменной и возвращать ее. Параметром функции будет местоположение book.txt для чтения и будет передан при вызове функции.
#read a book and return it as a string
def read_book(title_path):
with open(title_path, "r", encoding ="utf8") as current_file:
text = current_file.read()
text = text.replace("\n", "").replace("\r", "")
return text
Всего уникальных слов: Мы собираемся разработать другую функцию, называемую word_stats (), которая будет использовать словарь частот слов( вывод count_words_fast()/count_words() ) в качестве параметра. Функция вернет общее количество уникальных слов(сумма/общее количество ключей в словаре частот слов) и значение dict_values, содержащее общее количество их вместе, в виде кортежа.
# word_counts = count_words_fast(text)
def word_stats(word_counts):
num_unique = len(word_counts)
counts = word_counts.values()
return (num_unique, counts)
Вызов функций: Итак, наконец, мы собираемся прочитать книгу, например, английскую версию «Ромео и Джульетты», и собрать информацию о частоте слов, уникальных словах, общем количестве уникальных слов и т.д. Из функций.
text = read_book("./Books / English / shakespeare / Romeo and Juliet.txt")
word_counts = count_words_fast(text)
(num_unique, counts) = word_stats(word_counts)
print(num_unique, sum(counts))
Выход: 5118 40776С помощью созданных нами функций мы узнали, что в английской версии «Ромео и Джульетты» 5118 уникальных слов, а сумма частот уникальных слов составляет 40776. Мы можем узнать, какое слово встречается чаще всего в книге, и можем играть с различными версиями книг на разных языках, чтобы узнать о них и их статистике с помощью вышеуказанных функций.
Построение графиков Характерных особенностей книг
Мы собираемся построить график, (i)Длина книги в зависимости от количества уникальных слов для всех книг на разных языках, используя matplotlib. Мы импортируем панд, чтобы создать фрейм данных панд, который будет содержать информацию о книгах в виде столбцов.Мы классифицируем эти столбцы по различным категориям, таким как “язык”, “автор”, “название”, “длина” и “уникальный” .Чтобы построить длину книги по оси x и количество уникальных слов по оси y, мы кодируем:
import os
import pandas as pd
book_dir = "./Books"
os.listdir(book_dir)
stats = pd.DataFrame(columns =("language",
"author",
"title",
"length",
"unique"))
# check >>>stats
title_num = 1
for language in os.listdir(book_dir):
for author in os.listdir(book_dir+"/"+language):
for title in os.listdir(book_dir+"/"+language+"/"+author):
inputfile = book_dir+"/"+language+"/"+author+"/"+title
print(inputfile)
text = read_book(inputfile)
(num_unique, counts) = word_stats(count_words_fast(text))
stats.loc[title_num]= language,
author.capitalize(),
title.replace(".txt", ""),
sum(counts), num_unique
title_num+= 1
import matplotlib.pyplot as plt
plt.plot(stats.length, stats.unique, "bo-")
plt.loglog(stats.length, stats.unique, "ro")
stats[stats.language =="English"] #to check information on english books
plt.figure(figsize =(10, 10))
subset = stats[stats.language =="English"]
plt.loglog(subset.length,
subset.unique,
"o",
label ="English",
color ="crimson")
subset = stats[stats.language =="French"]
plt.loglog(subset.length,
subset.unique,
"o",
label ="French",
color ="forestgreen")
subset = stats[stats.language =="German"]
plt.loglog(subset.length,
subset.unique,
"o",
label ="German",
color ="orange")
subset = stats[stats.language =="Portuguese"]
plt.loglog(subset.length,
subset.unique,
"o",
label ="Portuguese",
color ="blueviolet")
plt.legend()
plt.xlabel("Book Length")
plt.ylabel("Number of Unique words")
plt.savefig("fig.pdf")
plt.show()
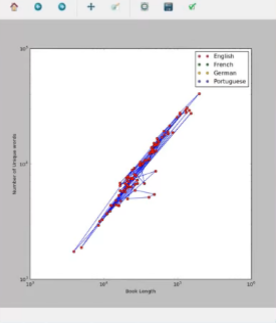
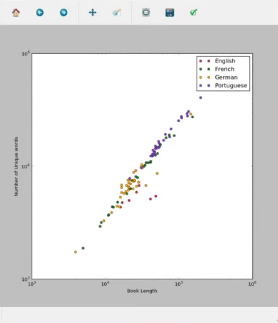
Выход: Мы построили два графика, первый из которых представляет каждую книгу на разных языках и автора как просто книгу. Красные точки на первый график представляют собой единую книгу, и они соединены синими линиями. График журнала создает дискретные точки [красный здесь], а линейный график создает линейные кривые [синий здесь], соединяющие точки. Второй график представляет собой логарифмический график, на котором книги на разных языках отображаются разными цветами [красный для английского, зеленый для французского и т.д.] В виде отдельных точек.
Эти графики помогают визуально анализировать факты о различных книгах яркого происхождения. Из графика мы узнали, что португальские книги длиннее по длине и содержат большее количество уникальных слов, чем немецкие или английские книги. Построение графиков таких данных оказывается большим подспорьем для лингвистов.