
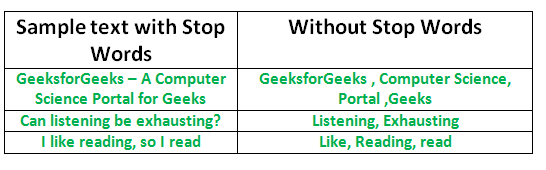
Процесс преобразования данных в то, что может понять компьютер, называется предварительной обработкой. Одной из основных форм предварительной обработки является отфильтровывание бесполезных данных. При обработке естественного языка бесполезные слова (данные) называются стоп-словами.
Что такое Стоп-слова?
Стоп-слова: Стоп-слово-это часто используемое слово (например, “the”, “a”, “an”, “in”), которое поисковая система запрограммирована игнорировать как при индексировании записей для поиска, так и при их извлечении в результате поискового запроса.
Мы бы не хотели, чтобы эти слова занимали место в нашей базе данных или отнимали драгоценное время на обработку. Для этого мы можем легко удалить их, сохранив список слов, которые вы считаете стоп-словами. NLTK(Natural Language Toolkit) в python содержит список стоп-слов, хранящихся на 16 различных языках. Вы можете найти их в каталоге nltk_data. главная страница/pratima/nltk_data/корпорации/стоп-слова-это адрес каталога.(Не забудьте изменить имя вашего домашнего каталога)
Чтобы проверить список стоп-слов, вы можете ввести следующие команды в оболочке python.
import nltk
from nltk.corpus import stopwords
print(stopwords.words('english')){‘ourselves’, ‘hers’, ‘between’, ‘yourself’, ‘but’, ‘again’, ‘there’, ‘about’, ‘once’, ‘during’, ‘out’, ‘very’, ‘having’, ‘with’, ‘they’, ‘own’, ‘an’, ‘be’, ‘some’, ‘for’, ‘do’, ‘its’, ‘yours’, ‘such’, ‘into’, ‘of’, ‘most’, ‘itself’, ‘other’, ‘off’, ‘is’, ‘s’, ‘am’, ‘or’, ‘who’, ‘as’, ‘from’, ‘him’, ‘each’, ‘the’, ‘themselves’, ‘until’, ‘below’, ‘are’, ‘we’, ‘these’, ‘your’, ‘his’, ‘through’, ‘don’, ‘nor’, ‘me’, ‘were’, ‘her’, ‘more’, ‘himself’, ‘this’, ‘down’, ‘should’, ‘our’, ‘their’, ‘while’, ‘above’, ‘both’, ‘up’, ‘to’, ‘ours’, ‘had’, ‘she’, ‘all’, ‘no’, ‘when’, ‘at’, ‘any’, ‘before’, ‘them’, ‘same’, ‘and’, ‘been’, ‘have’, ‘in’, ‘will’, ‘on’, ‘does’, ‘yourselves’, ‘then’, ‘that’, ‘because’, ‘what’, ‘over’, ‘why’, ‘so’, ‘can’, ‘did’, ‘not’, ‘now’, ‘under’, ‘he’, ‘you’, ‘herself’, ‘has’, ‘just’, ‘where’, ‘too’, ‘only’, ‘myself’, ‘which’, ‘those’, ‘i’, ‘after’, ‘few’, ‘whom’, ‘t’, ‘being’, ‘if’, ‘theirs’, ‘my’, ‘against’, ‘a’, ‘by’, ‘doing’, ‘it’, ‘how’, ‘further’, ‘was’, ‘here’, ‘than’}Примечание: Вы даже можете изменить список, добавив слова по вашему выбору в файл english .txt. в каталоге стоп-слов.
Удаление стоп-слов с помощью NLTK
Следующая программа удаляет стоп-слова из фрагмента текста:
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example_sent = """This is a sample sentence,
showing off the stop words filtration."""
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example_sent)
filtered_sentence = [w for w in word_tokens if not w.lower() in stop_words]
filtered_sentence = []
for w in word_tokens:
if w not in stop_words:
filtered_sentence.append(w)
print(word_tokens)
print(filtered_sentence)
Выход:
['This', 'is', 'a', 'sample', 'sentence', ',', 'showing',
'off', 'the', 'stop', 'words', 'filtration', '.']
['This', 'sample', 'sentence', ',', 'showing', 'stop',
'words', 'filtration', '.']Выполнение операций со стоп-словами в файле
В приведенном ниже коде, text.txt это исходный входной файл, в котором должны быть удалены стоп-слова. filteredtext.txt является выходным файлом. Это можно сделать с помощью следующего кода:
import io
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# word_tokenize accepts
# a string as an input, not a file.
stop_words = set(stopwords.words('english'))
file1 = open("text.txt")
# Use this to read file content as a stream:
line = file1.read()
words = line.split()
for r in words:
if not r in stop_words:
appendFile = open('filteredtext.txt','a')
appendFile.write(" "+r)
appendFile.close()
Именно так мы повышаем эффективность обработки нашего контента, удаляя слова, которые не способствуют каким-либо будущим операциям.

