
Как быстро создать мощную визуализацию исследовательского анализа данных
Как только вы получите хороший очищенный набор данных, следующим шагом будет Исследовательский анализ данных (EDA). EDA — это процесс выяснения того, что могут сообщить нам данные, и мы используем EDA для поиска закономерностей, взаимосвязей или аномалий для нашего последующего анализа. Несмотря на то, что в EDA существует почти подавляющее количество методов, одним из наиболее эффективных стартовых инструментов является график пар (также называемый матрицей диаграмм рассеяния). График пар позволяет нам видеть как распределение отдельных переменных, так и взаимосвязи между двумя переменными. Парные графики являются отличным методом определения тенденций для последующего анализа и, к счастью, легко реализуются в Python!
В этой статье мы расскажем о том, как начать и запустить графики пар на Python с использованием библиотеки визуализации seaborn. Мы увидим, как создать график пар по умолчанию для быстрого анализа наших данных и как настроить визуализацию для более глубокого понимания. Код для этого проекта доступен в виде записной книжки Jupyter на GitHub. Мы рассмотрим набор данных реального мира, состоящий из социально-экономических данных на уровне страны, собранных GapMinder.
Парные участки в Сиборне
Для начала нам нужно знать, какими данными мы располагаем. Мы можем загрузить социально-экономические данные в виде фрейма данных pandas и просмотреть столбцы:
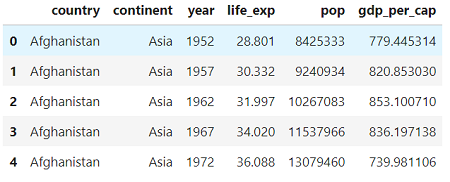
Каждая строка данных представляет собой наблюдение за одной страной за один год, а столбцы содержат переменные (данные в этом формате известны как аккуратные данные). Есть 2 категориальных столбца (страна и континент) и 4 числовых столбца. Столбцы достаточно понятны: life_exp ожидаемая продолжительность жизни при рождении в годах, pop численность населения и gdp_per_cap валовой внутренний продукт на человека в единицах международных долларов.
График пар по умолчанию в seaborn отображает только числовые столбцы, хотя позже мы будем использовать категориальные переменные для раскраски. Создание графика пар по умолчанию просто: мы загружаем библиотеку seaborn и вызываем pairplot функцию, передавая ей наш фрейм данных:
# Seaborn visualization library
import seaborn as sns
# Create the default pairplot
sns.pairplot(df)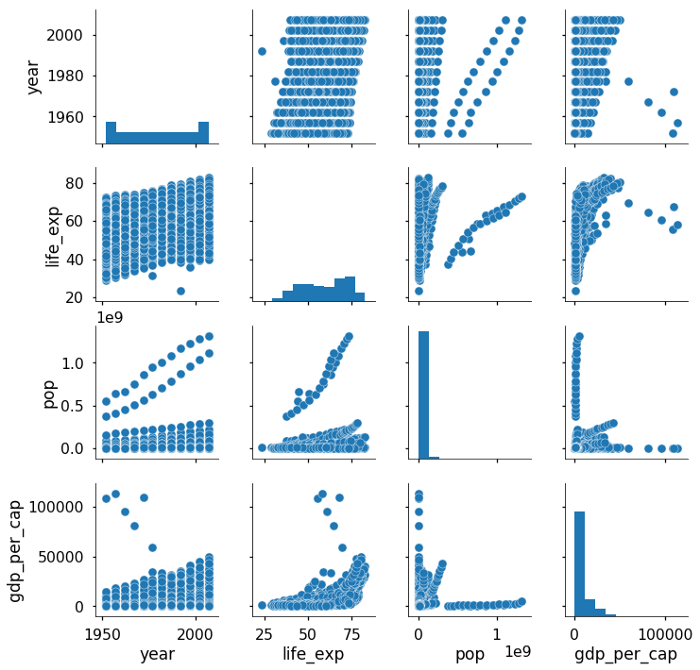
Я все еще поражен тем, что одна простая строка кода дает нам весь этот сюжет! График пар строится на двух основных фигурах: гистограмме и диаграмме рассеяния. Гистограмма по диагонали позволяет нам видеть распределение одной переменной, в то время как точечные диаграммы на верхнем и нижнем треугольниках показывают взаимосвязь (или ее отсутствие) между двумя переменными. Например, самый левый график во второй строке показывает точечную диаграмму life_exp в зависимости от года.
График пар по умолчанию сам по себе часто дает нам ценную информацию. Мы видим, что ожидаемая продолжительность жизни и ВВП на душу населения положительно коррелируют, показывая, что люди в странах с более высоким уровнем дохода, как правило, живут дольше (хотя это, конечно, не доказывает, что одно вызывает другое). Также похоже, что (к счастью) ожидаемая продолжительность жизни во всем мире со временем растет. Из гистограмм мы узнаем, что переменные населения и ВВП сильно смещены вправо. Чтобы лучше отобразить эти переменные на будущих графиках, мы можем преобразовать эти столбцы, взяв логарифм значений:
# Take the log of population and gdp_per_capita
df['log_pop'] = np.log10(df['pop'])
df['log_gdp_per_cap'] = np.log10(df['gdp_per_cap'])
# Drop the non-transformed columns
df = df.drop(columns = ['pop', 'gdp_per_cap'])Хотя этот график сам по себе может быть полезен в анализе, мы можем сделать его более ценным, раскрасив рисунки на основе категориальной переменной, такой как континент. Это также чрезвычайно просто в сиборне! Все, что нам нужно сделать, это использовать hue ключевое слово в sns.pairplot вызов функции:
sns.pairplot(df, hue = 'continent')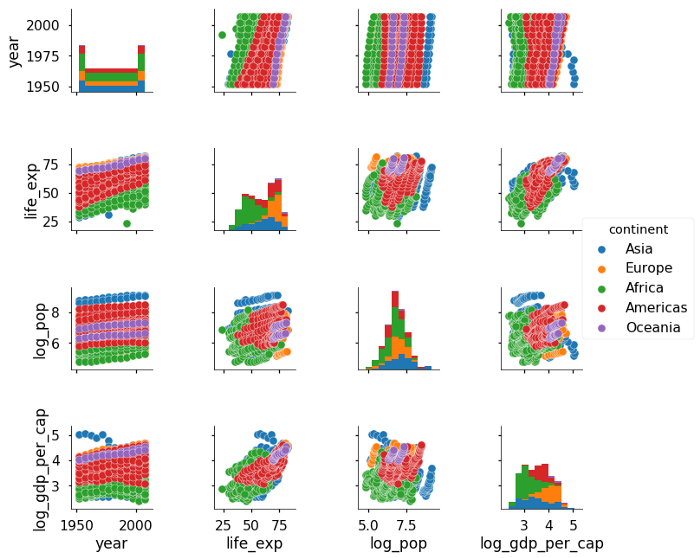
Теперь мы видим, что Океания и Европа, как правило, имеют самую высокую продолжительность жизни, а в Азии самое большое население. Обратите внимание, что наше логарифмическое преобразование численности населения и ВВП сделало эти переменные нормально распределенными, что дает более полное представление о значениях.
Этот график более информативен, но все же есть некоторые проблемы: я не склонен считать, что гистограммы с накоплением, как на диагоналях, очень интерпретируемы. Лучшим методом отображения одномерных (с одной переменной) распределений из нескольких категорий является график плотности. Мы можем обменять гистограмму на график плотности в вызове функции. Пока мы этим занимаемся, мы передадим некоторые ключевые слова на точечные диаграммы, чтобы изменить прозрачность, размер и цвет краев точек.
# Plot colored by continent for years 2000-2007
sns.pairplot(df[df['year'] >= 2000],
vars = ['life_exp', 'log_pop', 'log_gdp_per_cap'],
hue = 'continent', diag_kind = 'kde',
plot_kws = {'alpha': 0.6, 's': 80, 'edgecolor': 'k'},
size = 4);
# Title
plt.suptitle('Pair Plot of Socioeconomic Data for 2000-2007',
size = 28);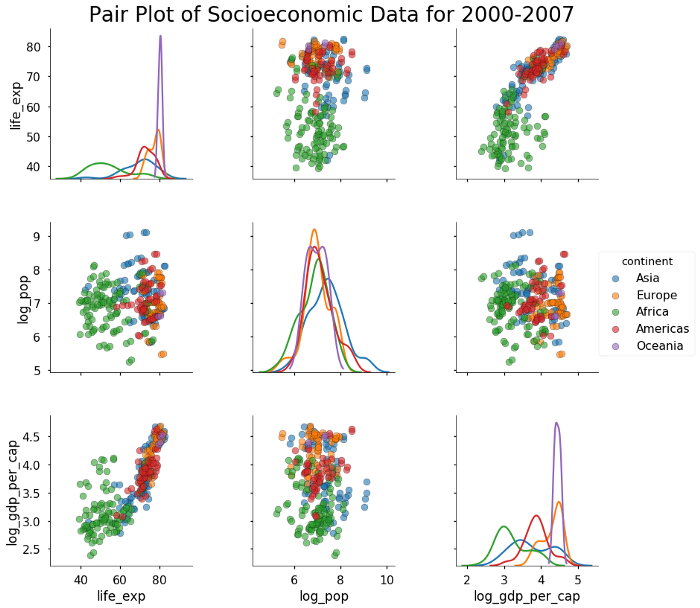
Это начинает выглядеть довольно мило! Если бы мы собирались заниматься моделированием, мы могли бы использовать информацию из этих графиков для обоснования нашего выбора. Например, мы знаем, что log_gdp_per_cap положительно коррелирует с life_exp, поэтому мы могли бы создать линейную модель для количественной оценки этой взаимосвязи. В этом посте мы будем придерживаться построения графиков, и, если мы хотим еще больше изучить наши данные, мы можем настроить графики пар с помощью класса PairGrid.
Настройка с помощью PairGrid
В отличие от sns.pairplot функции, sns.PairGrid это класс, который означает, что он автоматически не заполняет графики для нас. Вместо этого мы создаем экземпляр класса, а затем сопоставляем определенные функции с различными разделами сетки. Чтобы создать экземпляр PairGrid с нашими данными, мы используем следующий код, который также ограничивает переменные, которые мы покажем:
# Create an instance of the PairGrid class.
grid = sns.PairGrid(data= df_log[df_log['year'] == 2007],
vars = ['life_exp', 'log_pop',
'log_gdp_per_cap'], size = 4)Если бы мы отображали это, мы получили бы пустой график, потому что мы не сопоставили какие-либо функции с разделами сетки. Для парной сетки необходимо заполнить три раздела сетки: верхний треугольник, нижний треугольник и диагональ. Чтобы сопоставить графики с этими разделами, мы используем grid.map метод на разрезе. Например, для сопоставления точечной диаграммы с верхним треугольником мы используем:
# Map a scatter plot to the upper triangle
grid = grid.map_upper(plt.scatter, color = 'darkred')map_upper Метод принимает любую функцию, которая принимает два массива переменных (например, plt.scatter) и связанные с ними ключевые слова (такие как color). map_lower Метод точно такой же, но заполняет нижний треугольник сетки. То map_diag немного отличается, потому что он принимает функцию, которая принимает один массив (помните, что диагональ показывает только одну переменную). Примером может служить plt.hist которые мы используем для заполнения диагонального раздела ниже:
# Map a histogram to the diagonal
grid = grid.map_diag(plt.hist, bins = 10, color = 'darkred',
edgecolor = 'k')
# Map a density plot to the lower triangle
grid = grid.map_lower(sns.kdeplot, cmap = 'Reds')В этом случае мы используем оценку плотности ядра в 2-D (график плотности) на нижнем треугольнике. В совокупности этот код дает нам следующий сюжет:
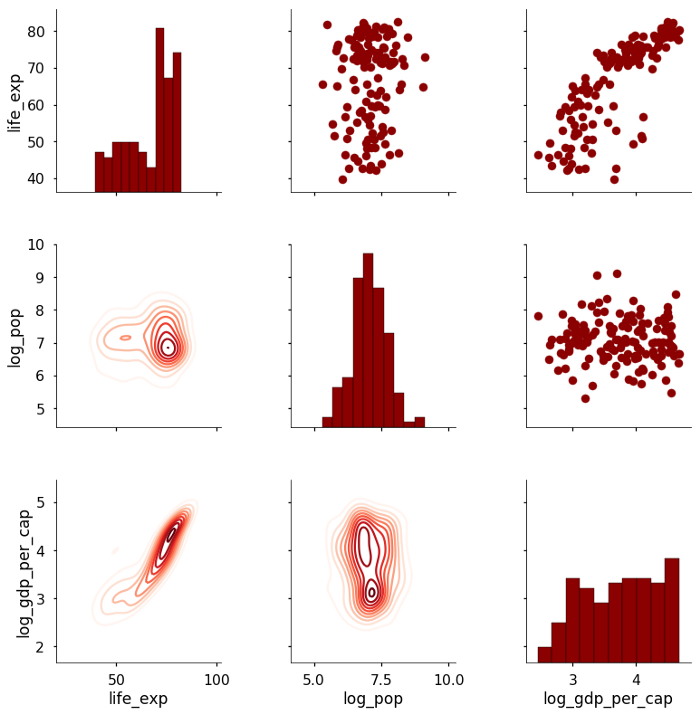
Реальные преимущества использования класса PairGrid возникают, когда мы хотим создавать пользовательские функции для отображения различной информации на графике. Например, я мог бы захотеть добавить коэффициент корреляции Пирсона между двумя переменными на диаграмму рассеяния. Для этого я бы написал функцию, которая принимает два массива, вычисляет статистику, а затем рисует ее на графике. Следующий код показывает, как это делается (заслуга этого ответа о переполнении стека):
# Function to calculate correlation coefficient between two arrays
def corr(x, y, **kwargs):
# Calculate the value
coef = np.corrcoef(x, y)[0][1]
# Make the label
label = r'$\rho$ = ' + str(round(coef, 2))
# Add the label to the plot
ax = plt.gca()
ax.annotate(label, xy = (0.2, 0.95), size = 20, xycoords = ax.transAxes)
# Create a pair grid instance
grid = sns.PairGrid(data= df[df['year'] == 2007],
vars = ['life_exp', 'log_pop', 'log_gdp_per_cap'], size = 4)
# Map the plots to the locations
grid = grid.map_upper(plt.scatter, color = 'darkred')
grid = grid.map_upper(corr)
grid = grid.map_lower(sns.kdeplot, cmap = 'Reds')
grid = grid.map_diag(plt.hist, bins = 10, edgecolor = 'k', color = 'darkred');Наша новая функция сопоставлена с верхним треугольником, потому что нам нужны два массива для вычисления коэффициента корреляции (обратите внимание также, что мы можем сопоставить несколько функций с разделами сетки). Это приводит к следующему сюжету:
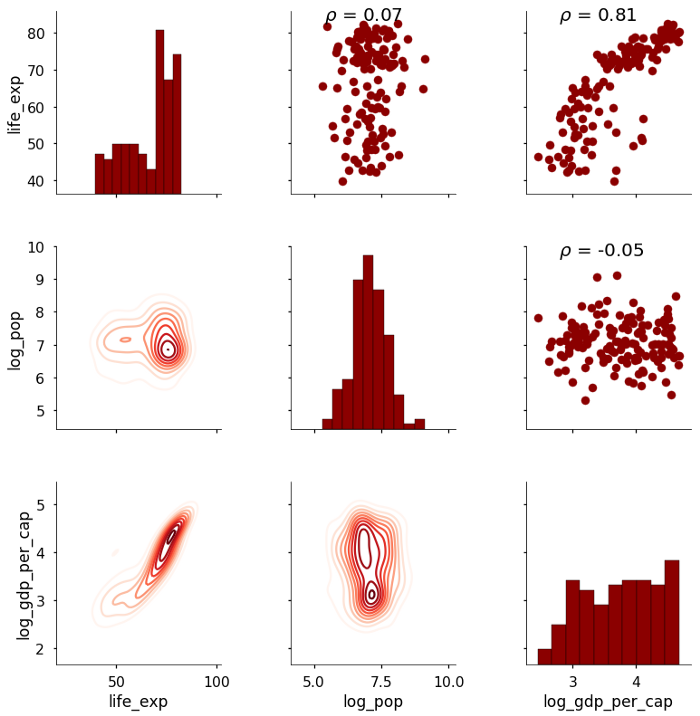
Коэффициент корреляции теперь отображается над диаграммой рассеяния. Это относительно простой пример, но мы можем использовать PairGrid для отображения любой функции, которую мы хотим, на графике. Мы можем добавить столько информации, сколько потребуется, при условии, что мы сможем понять, как написать функцию! В качестве последнего примера приведем график, который показывает сводную статистику по диагонали вместо графика.
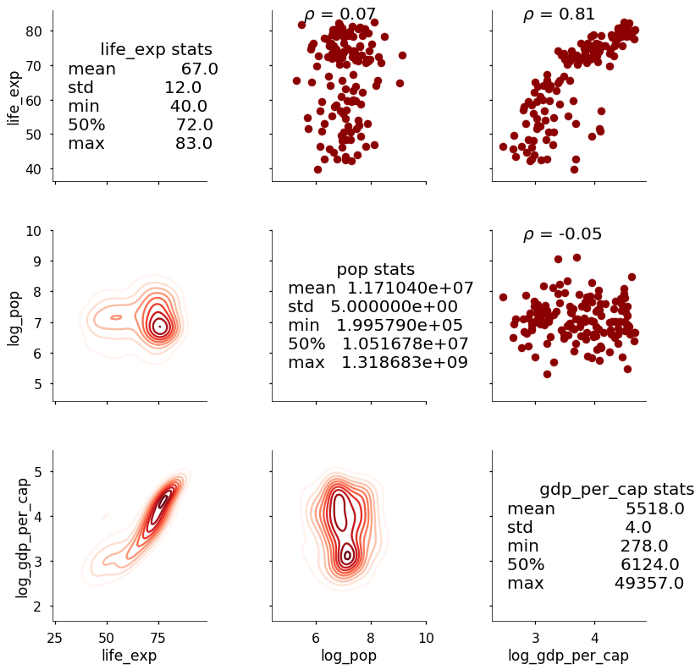
Это требует небольшой очистки, но это показывает общую идею; в дополнение к использованию любой существующей функции в библиотеке, например, matplotlib для отображения данных на рисунке, мы можем написать нашу собственную функцию для отображения пользовательской информации.
Вывод
Графики пар — это мощный инструмент для быстрого изучения распределений и взаимосвязей в наборе данных. Seaborn предоставляет простой метод по умолчанию для создания парных графиков, которые могут быть настроены и расширены с помощью класса сетки пар. В проекте по анализу данных большая часть ценности часто заключается не в ярком машинном обучении, а в простой визуализации данных. График пар предоставляет нам всесторонний первый взгляд на наши данные и является отличной отправной точкой в проектах по анализу данных.

