
Краткие сведения
В этой статье я покажу, как создавать нейронные сети с помощью Python и как объяснить Глубокое обучение бизнесу с помощью визуализации и создания объяснителя для предсказаний моделей.
Глубокое обучение — это тип машинного обучения, который имитирует то, как люди получают определенные типы знаний, и с годами он стал более популярным по сравнению со стандартными моделями. В то время как традиционные алгоритмы являются линейными, модели глубокого обучения, как правило, нейронные сети, расположены в иерархии возрастающей сложности и абстракции (поэтому “глубокое” в глубоком обучении).
Сегодня глубокое обучение настолько популярно, что многие компании хотят его использовать, даже если они не до конца понимают его. Часто специалистам по обработке данных сначала приходится упрощать эти сложные алгоритмы для бизнеса, а затем объяснять и обосновывать результаты моделей, что не всегда просто с нейронными сетями. Я думаю, что лучший способ сделать это-с помощью визуализации.
Я представлю некоторый полезный код на Python, который можно легко применить в других подобных случаях (просто скопируйте, вставьте, запустите) и пройдитесь по каждой строке кода с комментариями, чтобы вы могли воспроизвести примеры.
В частности, я пройду через:
- Настройка среды, tensorflow против pytorch.
- Разбивка искусственных нейронных сетей, ввод, вывод, скрытые слои, функции активации.
- Глубокое обучение с помощью глубоких нейронных сетей.
- Дизайн модели с помощью tensorflow/keras.
- Визуализация нейронных сетей с помощью python.
- Обучение и тестирование моделей.
- Объяснимость с шапом.
Установка
Существуют две основные библиотеки для построения нейронных сетей: TensorFlow (разработанная Google) и PyTorch (разработанная Facebook). Они могут выполнять аналогичные задачи, но первая более готова к производству, в то время как вторая хороша для создания быстрых прототипов, потому что ее легче изучать.
Эти две библиотеки пользуются популярностью у сообщества и бизнеса, потому что они могут использовать возможности графических процессоров NVIDIA. Это очень полезно, а иногда и необходимо для обработки больших наборов данных, таких как корпус текста или галерея изображений.
Для этого урока я собираюсь использовать TensorFlow и Keras, модуль более высокого уровня, более удобный для пользователя, чем чистый TensorFlow и PyTorch, хотя и немного медленнее.
Первым шагом является установка TensorFlow через терминал:
pip install tensorflowЕсли вы хотите включить поддержку GPU, вы можете прочитать официальная документация. После его настройки ваши инструкции на Python будут переведены на CUDA вашей машиной и обрабатывается графическими процессорами, поэтому ваши модели будут работать невероятно быстрее.
Теперь мы можем импортировать в наш ноутбук основные модули из Тензорный поток Керас и начните кодировать:
from tensorflow.keras import models, layers, utils, backend as K
import matplotlib.pyplot as plt
import shapИскусственные Нейронные Сети
ANN состоят из слоев с входным и выходным размером. Последнее определяется количеством нейроны (также называемый “узлами”), вычислительный блок, который соединяет взвешенные входные данные через функция активации (что помогает нейрону включаться/выключаться). Веса как и в большинстве алгоритмов машинного обучения , они случайным образом инициализируются и оптимизируются во время обучения, чтобы минимизировать функцию потерь.
Слои можно сгруппировать следующим образом:
- Входной слой выполняет задачу передачи входного вектора в нейронную сеть. Если у нас есть матрица из 3 объектов (форма N x 3), этот слой принимает 3 числа в качестве входных данных и передает те же 3 числа следующему слою.
- Скрытые слои представляют собой промежуточные узлы, они применяют несколько преобразований к числам, чтобы повысить точность конечного результата, а результат определяется количеством нейронов.
- Выходной слой, который возвращает конечный результат работы нейронной сети. Если мы выполняем простую двоичную классификацию или регрессию, выходной слой должен содержать только 1 нейрон (так что он возвращает только 1 число). В случае многоклассовой классификации с 5 различными классами выходной слой должен содержать 5 нейронов.
Простейшей формой ANN является Персептрон, модель только с одним слоем, очень похожая на модель линейной регрессии. Вопрос о том, что происходит внутри персептрона, эквивалентен вопросу о том, что происходит внутри одного узла многослойной нейронной сети… давайте разберем это.
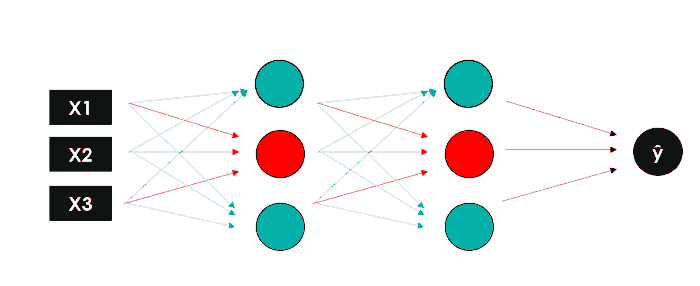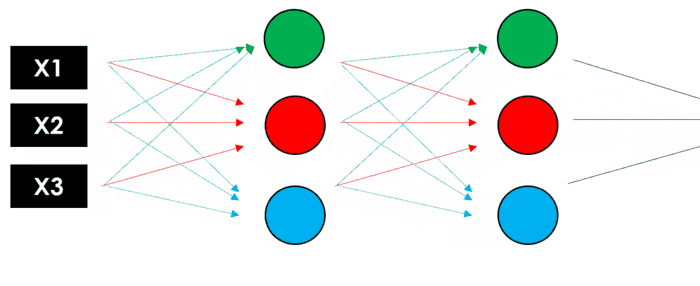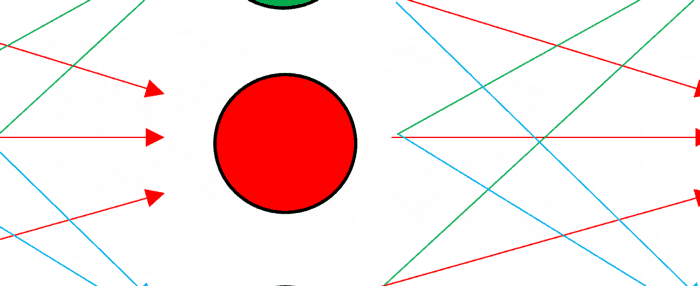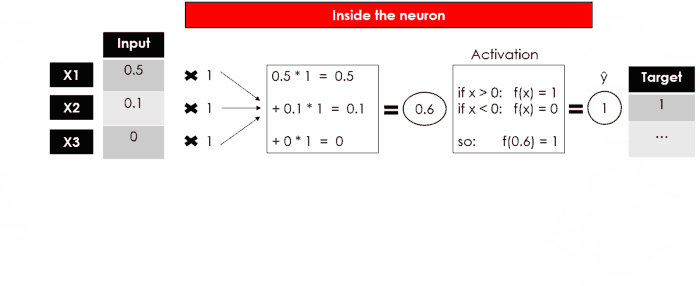
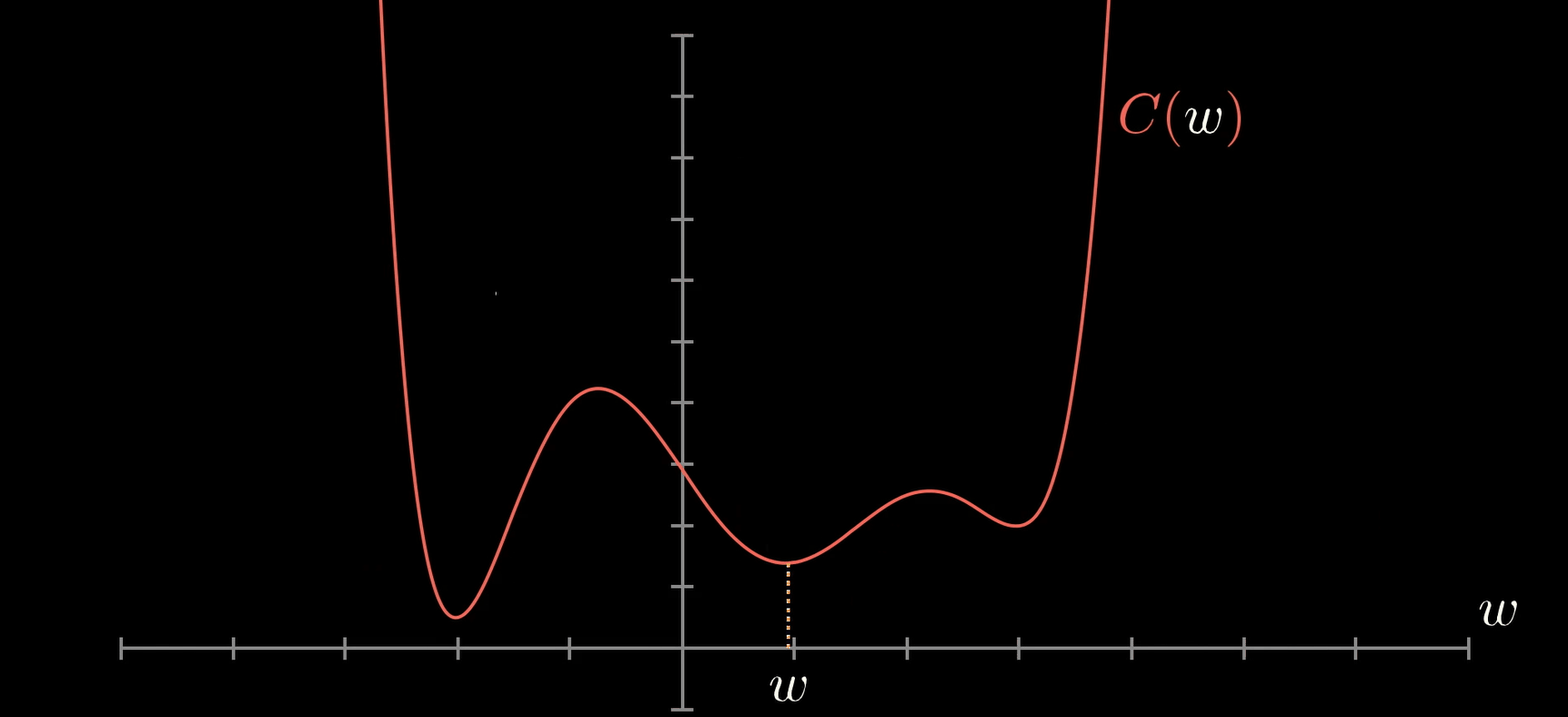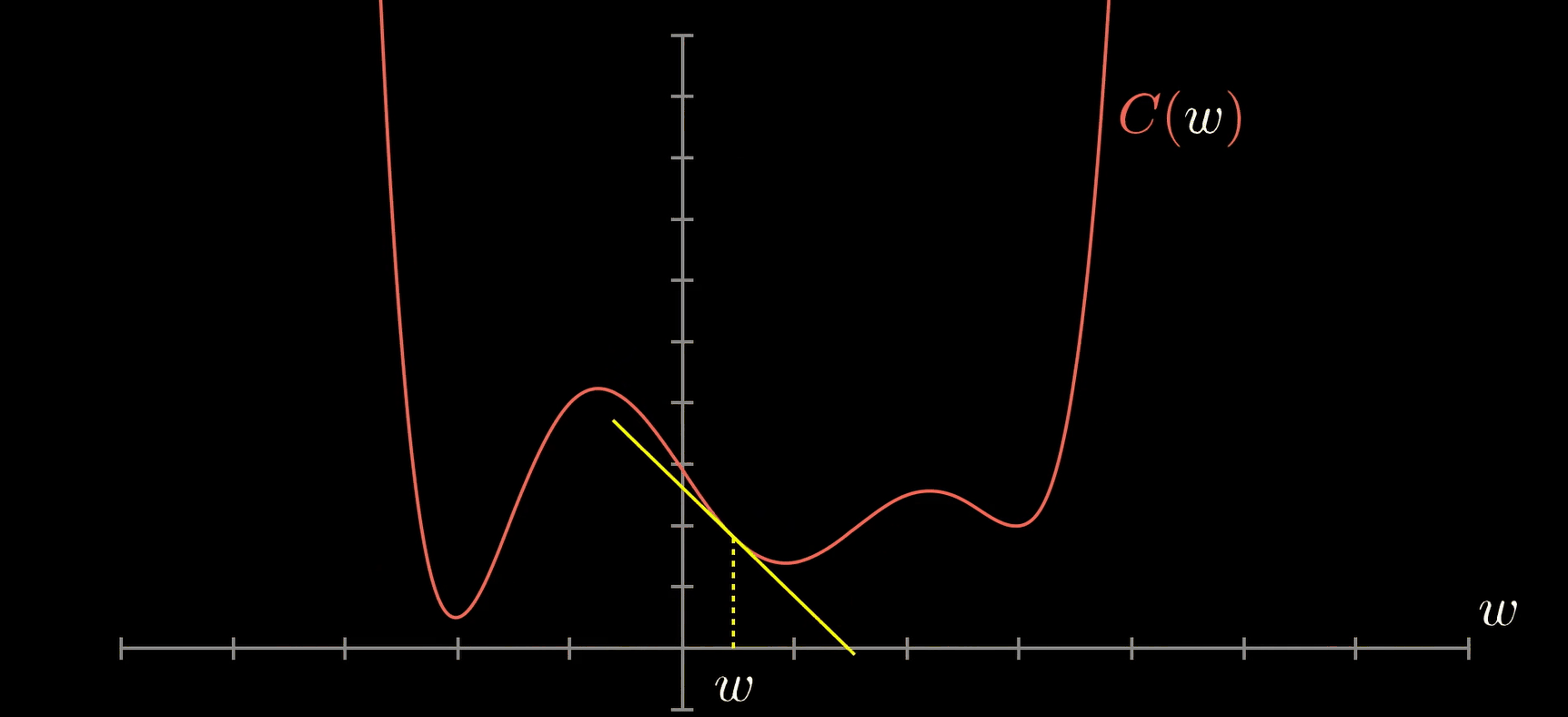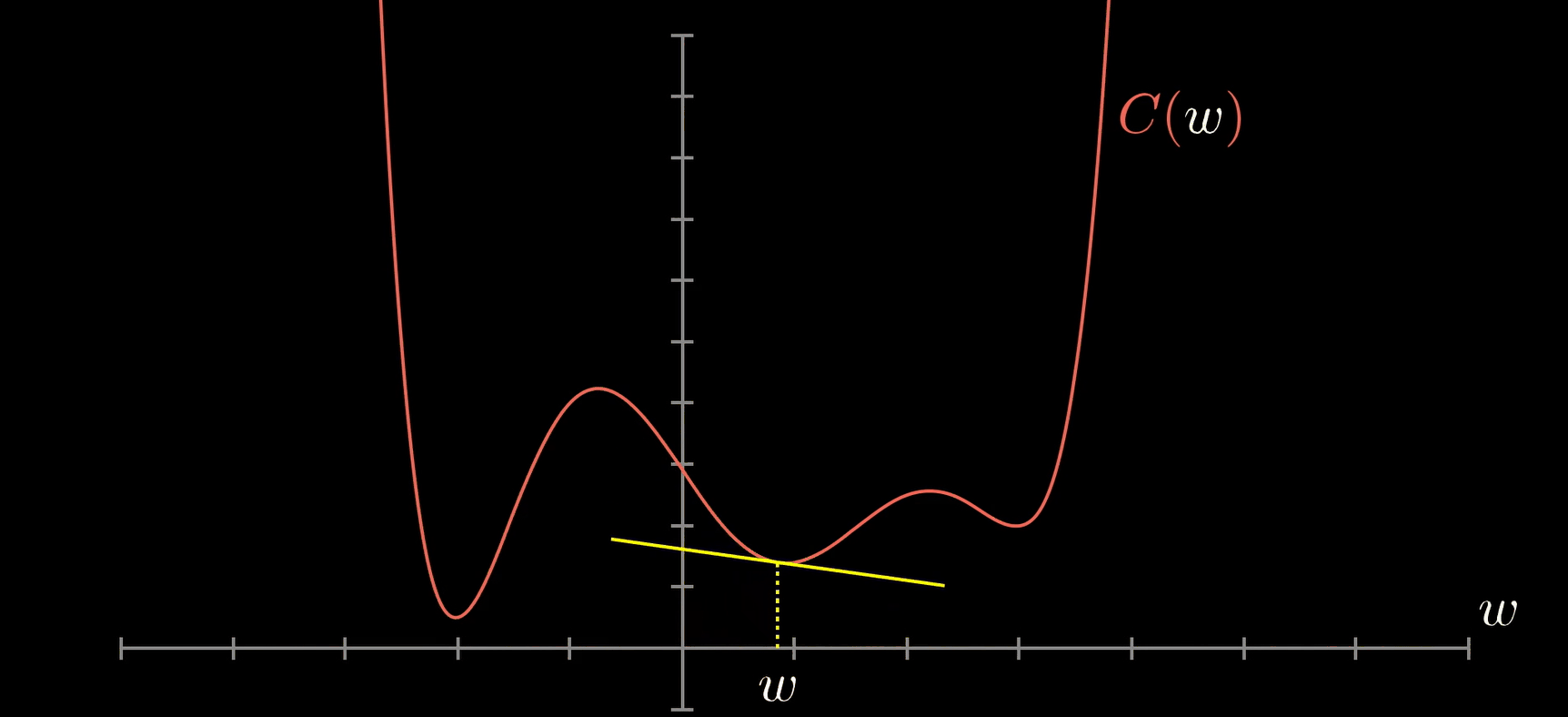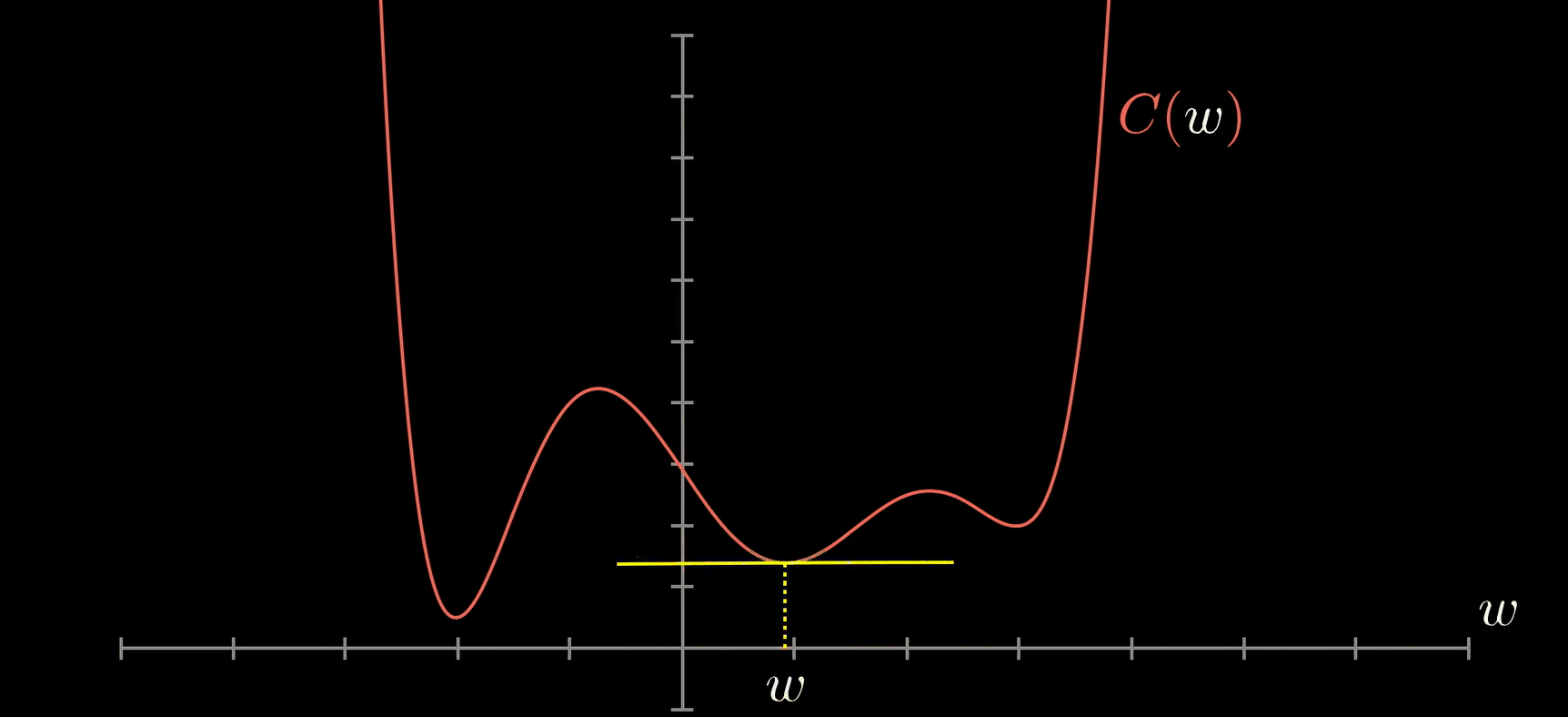
Допустим, у нас есть набор данных из N строк, 3 объектов и 1 целевой переменной (т. е. двоичная 1/0).:

Как и в любом другом случае использования машинного обучения, мы собираемся обучить модель прогнозированию цели, используя функции строка за строкой. Давайте начнем с первого ряда:

Что означает “обучение модели”? Поиск наилучших параметров в математической формуле, которые минимизируют ошибку ваших прогнозов. В регрессионных моделях (т. е. линейная регрессия) вы должны найти наилучшие веса, в древовидных моделях (т. Е. случайный лес) речь идет о нахождении наилучших точек разделения…

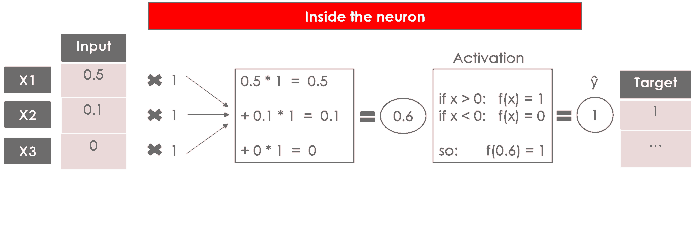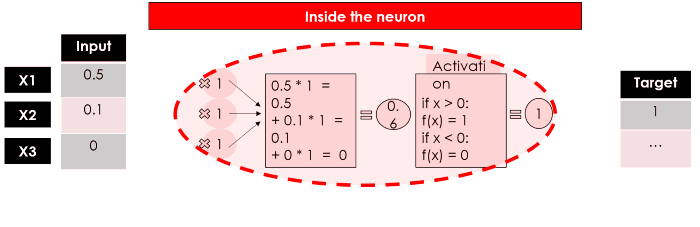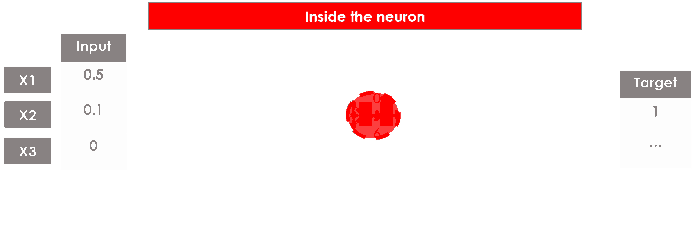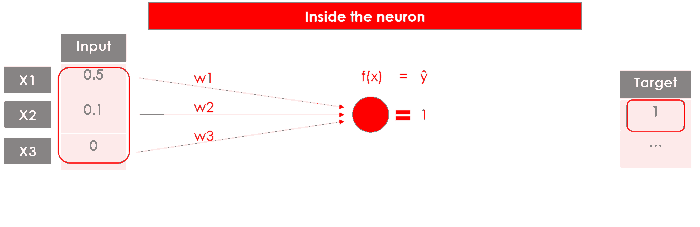
Обычно веса инициализируются случайным образом, а затем корректируются по мере продолжения обучения. Здесь я просто установлю их все как 1:

До сих пор мы не делали ничего, что отличалось бы от линейной регрессии (что довольно просто для понимания бизнеса). Теперь, вот обновление от линейной модели Σ(xi*wi)=Y до нелинейной модели f(Σ(xi*wi))=Y … введите функцию активации.

Функция активации определяет выходные данные этого узла. Их много, и можно даже создать некоторые пользовательские функции, вы можете найти подробную информацию в официальной документации и ознакомиться с этой шпаргалкой. Если бы мы задали простую линейную функцию в нашем примере, то мы бы ничем не отличались от модели линейной регрессии.
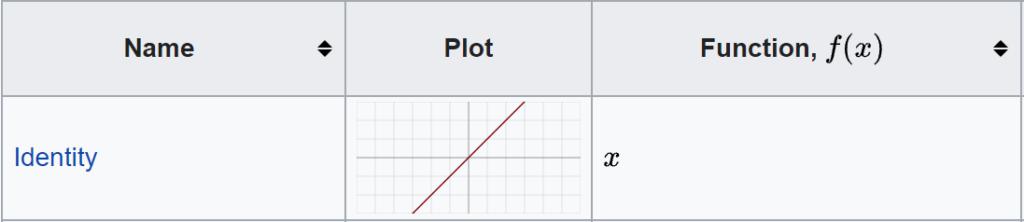
Я буду использовать функцию активации двоичного шага, которая возвращает только 1 или 0:

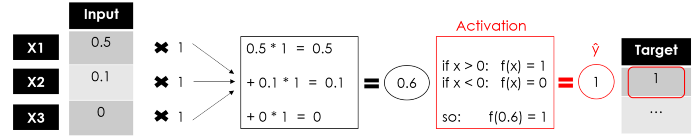
У нас есть выход нашего персептрона, однослойной нейронной сети, которая принимает некоторые входные данные и возвращает 1 выходной. Теперь обучение модели будет продолжаться путем сравнения выходных данных с целевыми, вычисления ошибки и оптимизации весов, повторяя весь процесс снова и снова.
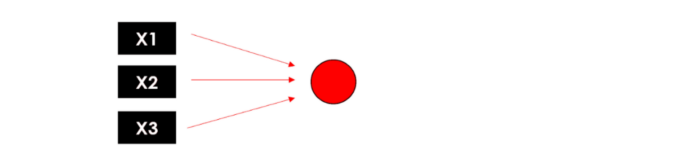
И вот общее представление нейрона:
Глубокие Нейронные Сети
Можно сказать, что все модели глубокого обучения являются нейронными сетями, но не все нейронные сети являются моделями глубокого обучения. Вообще говоря, “Глубокое” обучение применяется, когда алгоритм имеет по крайней мере 2 скрытых слоя (таким образом, всего 4 слоя, включая ввод и вывод).
Представьте, что процесс репликации нейрона повторяется 3 раза одновременно: поскольку каждый узел (взвешенная сумма и функция активации) возвращает значение, у нас будет первый скрытый слой с 3 выходами.
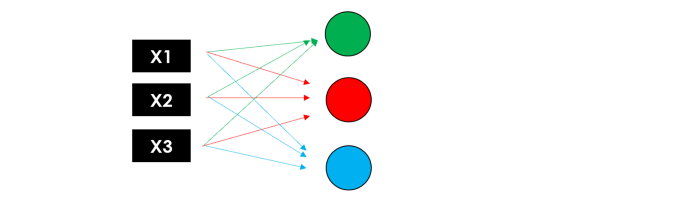
Теперь давайте сделаем это снова, используя эти 3 выхода в качестве входных данных для второго скрытого слоя, который возвращает 3 новых числа. Наконец, мы добавим выходной слой (только 1 узел), чтобы получить окончательное предсказание нашей модели.
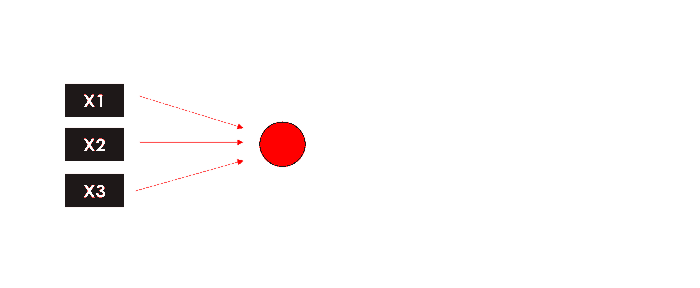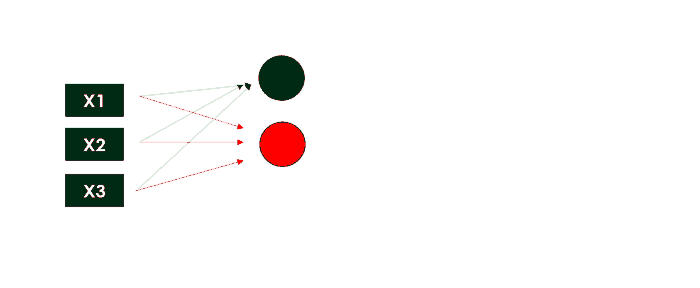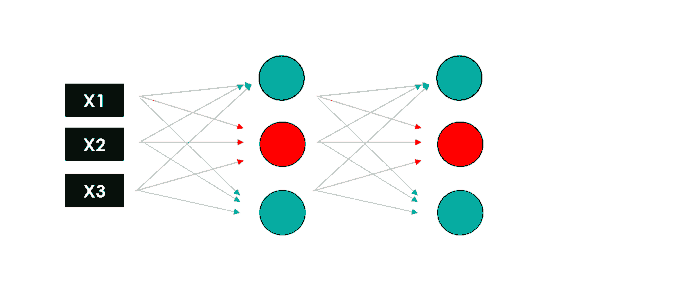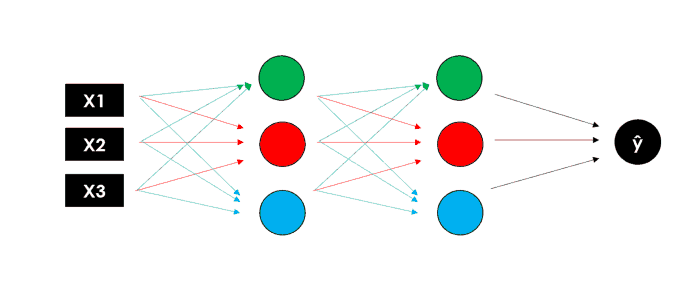
Помните, что слои могут иметь разное количество нейронов и различную функцию активации, и в каждом узле веса обучаются для оптимизации конечного результата. Вот почему, чем больше слоев вы добавляете, тем больше становится количество обучаемых параметров.
Теперь вы можете просмотреть полную картину нейронной сети:

Пожалуйста, обратите внимание, что для того, чтобы все было как можно проще, я не упомянул некоторые детали, которые могут не представлять интереса для Бизнеса, но специалист по обработке данных определенно должен быть в курсе. В частности:
- Смещение: внутри каждого нейрона линейная комбинация входных данных и весов также включает смещение, аналогичное константе в линейном уравнении, поэтому полная формула нейрона такова
f( Σ(Xi * Wi ) + смещение )
- Обратное распространение: во время обучения модель обучается, распространяя ошибку обратно в узлы и обновляя параметры (веса и смещения), чтобы минимизировать потери.

- Градиентный спуск: алгоритм оптимизации, используемый для обучения нейронных сетей, который находит локальный минимум функции потерь, делая повторяющиеся шаги в направлении самого крутого спуска.
Дизайн Модели
Самый простой способ построить нейронную сеть с помощью TensorFlow-это использовать последовательный класс Keras. Давайте используем его, чтобы сделать персептрон из нашего предыдущего примера, то есть модель только с одним плотным слоем. Это самый базовый слой, поскольку он передает все свои входные данные всем нейронам, причем каждый нейрон обеспечивает один выход.
# define the function
import tensorflow as tf
def binary_step_activation(x):
##return 1 if x>0 else 0
return K.switch(x>0, tf.math.divide(x,x), tf.math.multiply(x,0))
# build the model
model = models.Sequential(name="Perceptron", layers=[
layers.Dense(
name="dense",
input_dim=3,
units=1,
activation=binary_step_activation
)
])Теперь давайте попробуем перейти от Персептрона к Глубокой нейронной сети. Вероятно, вы собираетесь задать себе несколько вопросов:
- Сколько слоев? Правильный ответ: “попробуйте разные варианты и посмотрите, что работает”. Я обычно работаю с 2 плотными скрытыми слоями с отсевом, методом, который уменьшает перенапряжение, случайным образом устанавливая входные данные на 0. Скрытые слои полезны для преодоления нелинейности данных, поэтому, если вам не нужна нелинейность, вы можете избежать скрытых слоев. Слишком много скрытых слоев приведет к переоснащению.
- Сколько нейронов? Количество скрытых нейронов должно быть между размером входного слоя и размером выходного слоя. Мое эмпирическое правило таково (количество входов + 1 выход)/2.
- Какая функция активации? Их много, и мы не можем сказать, что один из них абсолютно лучше. В любом случае, наиболее часто используемой является ReLU, кусочно-линейная функция, которая возвращает результат только в том случае, если он положительный, и в основном используется для скрытых слоев. Кроме того, выходной уровень должен иметь активацию, совместимую с ожидаемым выходом. Например, линейная функция подходит для задач регрессии, в то время как сигмоида часто используется для классификации.
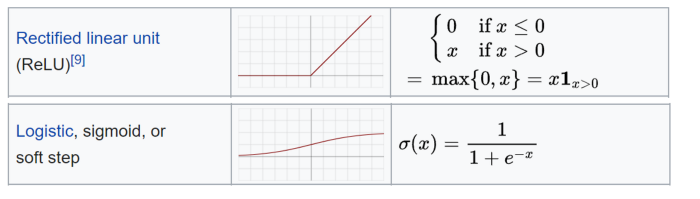
Я собираюсь принять входной набор данных из N объектов и 1 двоичной целевой переменной (скорее всего, вариант использования классификации).
n_features = 10
model = models.Sequential(name="DeepNN", layers=[
### hidden layer 1
layers.Dense(name="h1", input_dim=n_features,
units=int(round((n_features+1)/2)),
activation='relu'),
layers.Dropout(name="drop1", rate=0.2),
### hidden layer 2
layers.Dense(name="h2", units=int(round((n_features+1)/4)),
activation='relu'),
layers.Dropout(name="drop2", rate=0.2),
### layer output
layers.Dense(name="output", units=1, activation='sigmoid')
])
model.summary()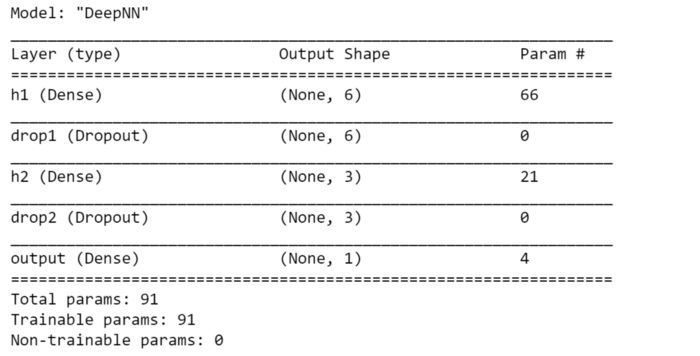
Пожалуйста, обратите внимание, что последовательный класс-не единственный способ построения нейронной сети с помощью Keras. Класс модели обеспечивает большую гибкость и контроль над слоями, и его можно использовать для создания более сложных моделей с несколькими входами/выходами. Есть два основных отличия:
- Входной слой должен быть указан, в то время как в Последовательном классе он подразумевается во входном измерении первого плотного слоя.
- Слои сохраняются как объекты и могут быть применены к выходам других слоев, например: выход = слой(…)(вход)
Вот как вы можете использовать класс модели для построения нашего персептрона и DeepNN:
#
inputs = layers.Input(name="input", shape=(3,))
outputs = layers.Dense(name="output", units=1,
activation='linear')(inputs)
model = models.Model(inputs=inputs, outputs=outputs,
name="Perceptron")
# DeepNN
### layer input
inputs = layers.Input(name="input", shape=(n_features,))
### hidden layer 1
h1 = layers.Dense(name="h1", units=int(round((n_features+1)/2)), activation='relu')(inputs)
h1 = layers.Dropout(name="drop1", rate=0.2)(h1)
### hidden layer 2
h2 = layers.Dense(name="h2", units=int(round((n_features+1)/4)), activation='relu')(h1)
h2 = layers.Dropout(name="drop2", rate=0.2)(h2)
###
outputs = layers.Dense(name="output", units=1, activation='sigmoid')(h2)
model = models.Model(inputs=inputs, outputs=outputs, name="DeepNN")Всегда можно проверить, совпадает ли количество параметров в сводке модели с количеством параметров из последовательности.
Визуализация
Помните, что мы рассказываем историю бизнесу, и визуализация-наш лучший союзник. Я подготовил функцию для построения структуры искусственной нейронной сети на основе ее модели тензорного потока, вот полный код:
'''
Extract info for each layer in a keras model.
'''
def utils_nn_config(model):
lst_layers = []
if "Sequential" in str(model): #-> Sequential doesn't show the input layer
layer = model.layers[0]
lst_layers.append({"name":"input", "in":int(layer.input.shape[-1]), "neurons":0,
"out":int(layer.input.shape[-1]), "activation":None,
"params":0, "bias":0})
for layer in model.layers:
try:
dic_layer = {"name":layer.name, "in":int(layer.input.shape[-1]), "neurons":layer.units,
"out":int(layer.output.shape[-1]), "activation":layer.get_config()["activation"],
"params":layer.get_weights()[0], "bias":layer.get_weights()[1]}
except:
dic_layer = {"name":layer.name, "in":int(layer.input.shape[-1]), "neurons":0,
"out":int(layer.output.shape[-1]), "activation":None,
"params":0, "bias":0}
lst_layers.append(dic_layer)
return lst_layers
'''
Plot the structure of a keras neural network.
'''
def visualize_nn(model, description=False, figsize=(10,8)):
## get layers info
lst_layers = utils_nn_config(model)
layer_sizes = [layer["out"] for layer in lst_layers]
## fig setup
fig = plt.figure(figsize=figsize)
ax = fig.gca()
ax.set(title=model.name)
ax.axis('off')
left, right, bottom, top = 0.1, 0.9, 0.1, 0.9
x_space = (right-left) / float(len(layer_sizes)-1)
y_space = (top-bottom) / float(max(layer_sizes))
p = 0.025
## nodes
for i,n in enumerate(layer_sizes):
top_on_layer = y_space*(n-1)/2.0 + (top+bottom)/2.0
layer = lst_layers[i]
color = "green" if i in [0, len(layer_sizes)-1] else "blue"
color = "red" if (layer['neurons'] == 0) and (i > 0) else color
### add description
if (description is True):
d = i if i == 0 else i-0.5
if layer['activation'] is None:
plt.text(x=left+d*x_space, y=top, fontsize=10, color=color, s=layer["name"].upper())
else:
plt.text(x=left+d*x_space, y=top, fontsize=10, color=color, s=layer["name"].upper())
plt.text(x=left+d*x_space, y=top-p, fontsize=10, color=color, s=layer['activation']+" (")
plt.text(x=left+d*x_space, y=top-2*p, fontsize=10, color=color, s="Σ"+str(layer['in'])+"[X*w]+b")
out = " Y" if i == len(layer_sizes)-1 else " out"
plt.text(x=left+d*x_space, y=top-3*p, fontsize=10, color=color, s=") = "+str(layer['neurons'])+out)
### circles
for m in range(n):
color = "limegreen" if color == "green" else color
circle = plt.Circle(xy=(left+i*x_space, top_on_layer-m*y_space-4*p), radius=y_space/4.0, color=color, ec='k', zorder=4)
ax.add_artist(circle)
### add text
if i == 0:
plt.text(x=left-4*p, y=top_on_layer-m*y_space-4*p, fontsize=10, s=r'$X_{'+str(m+1)+'}$')
elif i == len(layer_sizes)-1:
plt.text(x=right+4*p, y=top_on_layer-m*y_space-4*p, fontsize=10, s=r'$y_{'+str(m+1)+'}$')
else:
plt.text(x=left+i*x_space+p, y=top_on_layer-m*y_space+(y_space/8.+0.01*y_space)-4*p, fontsize=10, s=r'$H_{'+str(m+1)+'}$')
## links
for i, (n_a, n_b) in enumerate(zip(layer_sizes[:-1], layer_sizes[1:])):
layer = lst_layers[i+1]
color = "green" if i == len(layer_sizes)-2 else "blue"
color = "red" if layer['neurons'] == 0 else color
layer_top_a = y_space*(n_a-1)/2. + (top+bottom)/2. -4*p
layer_top_b = y_space*(n_b-1)/2. + (top+bottom)/2. -4*p
for m in range(n_a):
for o in range(n_b):
line = plt.Line2D([i*x_space+left, (i+1)*x_space+left],
[layer_top_a-m*y_space, layer_top_b-o*y_space],
c=color, alpha=0.5)
if layer['activation'] is None:
if o == m:
ax.add_artist(line)
else:
ax.add_artist(line)
plt.show()Давайте попробуем это на наших 2 моделях, сначала на персептроне:
visualize_nn(model, description=True, figsize=(10,8))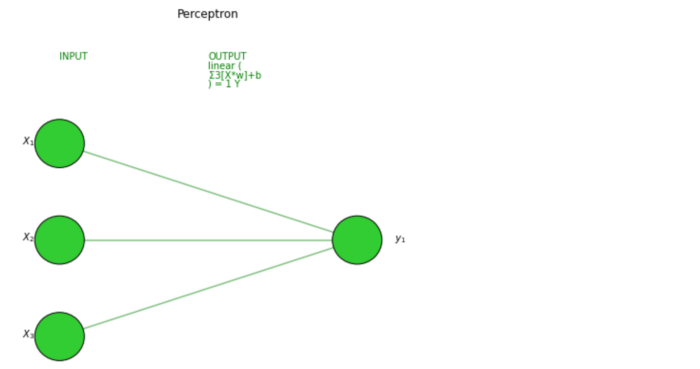
затем Глубокая Нейронная сеть:
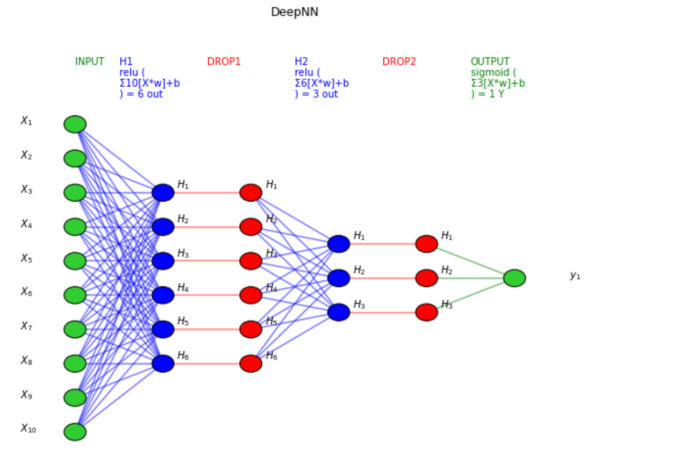
TensorFlow также предоставляет инструмент для построения структуры модели, вы можете использовать его для более сложных нейронных сетей с более сложными слоями (CNN, RNN, …). Иногда это немного сложно настроить, если у вас есть проблемы, этот пост может помочь.
utils.plot_model(model, to_file='model.png', show_shapes=True, show_layer_names=True)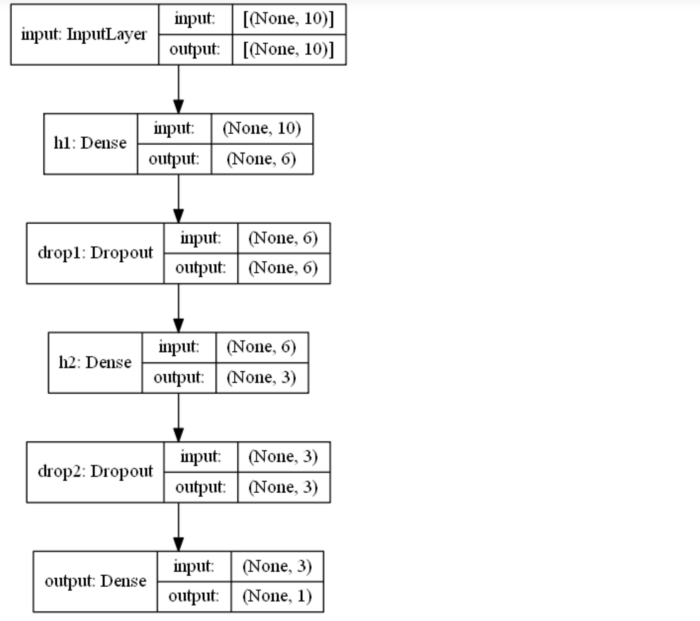
Это сохранит это изображение на вашем ноутбуке, поэтому, если вы просто хотите отобразить его на своем ноутбуке, вы можете просто выполнить следующее, чтобы удалить файл:
import os
os.remove('model.png')Тренируйтесь и тестируйте
Наконец, пришло время обучить нашу модель глубокого обучения. Для того, чтобы он запустился, мы должны “скомпилировать”, или, другими словами, нам нужно определить Оптимизатор, то Функция потерь, и Метрика. Я обычно использую Адам оптимизатор, заменяющий алгоритм оптимизации градиентного спуска (лучший среди адаптивных оптимизаторов). Другие аргументы зависят от варианта использования.
В задачах (двоичной) классификации следует использовать (бинарная) Перекрестная энтропия потеря, которая сравнивает каждую из прогнозируемых вероятностей с фактическим выходом класса. Что касается показателей, мне нравится отслеживать как Точность и F1-оценка, метрика, которая объединяет Точность и Отзыв (последнее должно быть реализовано, поскольку оно еще не включено в Тензорный поток).
# define metrics
def Recall(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def Precision(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
def F1(y_true, y_pred):
precision = Precision(y_true, y_pred)
recall = Recall(y_true, y_pred)
return 2*((precision*recall)/(precision+recall+K.epsilon()))
# compile the neural network
model.compile(optimizer='adam', loss='binary_crossentropy',
metrics=['accuracy',F1])С другой стороны, в задачах регрессии я обычно задаю МЭЙ как потеря, так и R-квадрат в качестве показателя.
# define metrics
def R2(y, y_hat):
ss_res = K.sum(K.square(y - y_hat))
ss_tot = K.sum(K.square(y - K.mean(y)))
return ( 1 - ss_res/(ss_tot + K.epsilon()) )
# compile the neural network
model.compile(optimizer='adam', loss='mean_absolute_error',
metrics=[R2])Перед началом обучения нам также необходимо решить, Эпохи и Партии: поскольку набор данных может быть слишком большим для одновременной обработки, он разбивается на пакеты (чем больше размер пакета, тем больше места в памяти вам нужно). Обратное распространение и последующее обновление параметров происходят каждую партию. Эпоха-это один проход по полному набору тренировок. Итак, если у вас 100 наблюдений, а размер пакета равен 20, для завершения 1 эпохи потребуется 5 пакетов. Размер пакета должен быть кратен 2 (обычно: 32, 64, 128, 256), поскольку компьютеры обычно организуют память мощностью 2. Я обычно начинаю со 100 эпох с размером пакета 32.
Во время обучения мы ожидаем, что показатели улучшатся, а потери будут уменьшаться от эпохи к эпохе. Кроме того, рекомендуется хранить часть данных (20-30%) для утверждение. Другими словами, модель выделит эту часть данных для оценки потерь и показателей в конце каждой эпохи, вне обучения.
Предполагая, что вы подготовили свои данные для некоторых X и y массивы (если нет, вы можете просто генерировать случайные данные, такие как
import numpy as np
X = np.random.rand(1000,10)
y = np.random.choice([1,0], size=1000)вы можете запустить и визуализировать обучение следующим образом:
# train/validation
training = model.fit(x=X, y=y, batch_size=32, epochs=100, shuffle=True, verbose=0, validation_split=0.3)
# plot
metrics = [k for k in training.history.keys() if ("loss" not in k) and ("val" not in k)]
fig, ax = plt.subplots(nrows=1, ncols=2, sharey=True, figsize=(15,3))
## training
ax[0].set(title="Training")
ax11 = ax[0].twinx()
ax[0].plot(training.history['loss'], color='black') ax[0].set_xlabel('Epochs')
ax[0].set_ylabel('Loss', color='black')
for metric in metrics:
ax11.plot(training.history[metric], label=metric) ax11.set_ylabel("Score", color='steelblue')
ax11.legend()
## validation
ax[1].set(title="Validation")
ax22 = ax[1].twinx()
ax[1].plot(training.history['val_loss'], color='black') ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('Loss', color='black')
for metric in metrics:
ax22.plot(training.history['val_'+metric], label=metric) ax22.set_ylabel("Score", color="steelblue")
plt.show()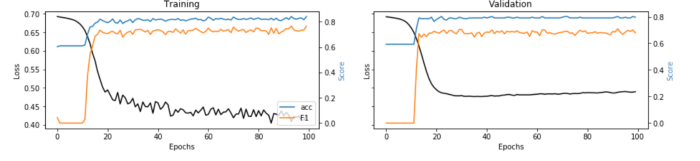
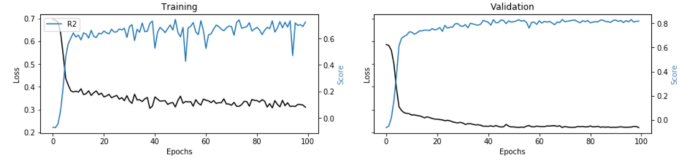
Эти графики взяты из двух реальных примеров использования, в которых сравниваются стандартные алгоритмы машинного обучения с нейронными сетями (ссылки под каждым изображением).
Объяснимость
Мы обучили и протестировали нашу модель, но до сих пор не убедили Бизнес в результатах… что мы можем сделать? Легко, мы создаем объяснитель, чтобы показать, что наша модель глубокого обучения-это не черный ящик.
Я нахожу Шап очень хорошо работает с нейронными сетями: для каждого прогноза он может оценить вклад каждой функции в значение, предсказанное моделью. В принципе, это отвечает на вопрос “почему модель говорит, что это 1, а не 0?”.
Вы можете использовать следующий код:
'''
Use shap to build an a explainer.
:parameter
:param model: model instance (after fitting)
:param X_names: list
:param X_instance: array of size n x 1 (n,)
:param X_train: array - if None the model is simple machine learning, if not None then it's a deep learning model
:param task: string - "classification", "regression"
:param top: num - top features to display
:return
dtf with explanations
'''
def explainer_shap(model, X_names, X_instance, X_train=None, task="classification", top=10):
## create explainer
### machine learning
if X_train is None:
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_instance)
### deep learning
else:
explainer = shap.DeepExplainer(model, data=X_train[:100])
shap_values = explainer.shap_values(X_instance.reshape(1,-1))[0].reshape(-1)
## plot
### classification
if task == "classification":
shap.decision_plot(explainer.expected_value, shap_values, link='logit', feature_order='importance',
features=X_instance, feature_names=X_names, feature_display_range=slice(-1,-top-1,-1))
### regression
else:
shap.waterfall_plot(explainer.expected_value[0], shap_values,
features=X_instance, feature_names=X_names, max_display=top)Пожалуйста, обратите внимание, что вы можете использовать эту функцию и в других моделях машинного обучения (например, Линейная регрессия, Случайный лес), а не только в нейронных сетях. Как вы можете прочитать из кода, если Аргумент X_train сохраняется как Нет, моя функция предполагает, что это не Глубокое обучение.
Давайте проверим это на примерах классификации и регрессии:
i = 1
explainer_shap(model,
X_names=list_feature_names,
X_instance=X[i],
X_train=X,
task="classification", #task="regression"
top=10)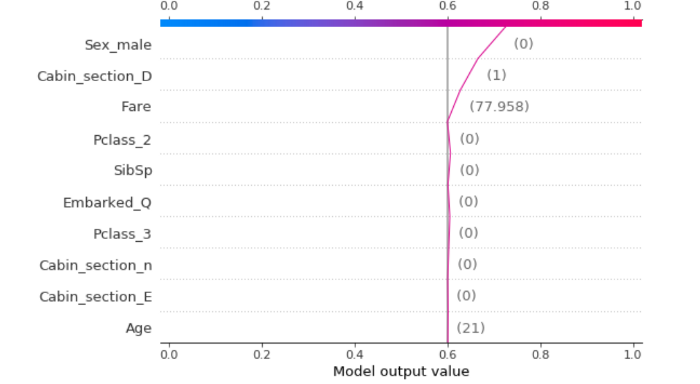
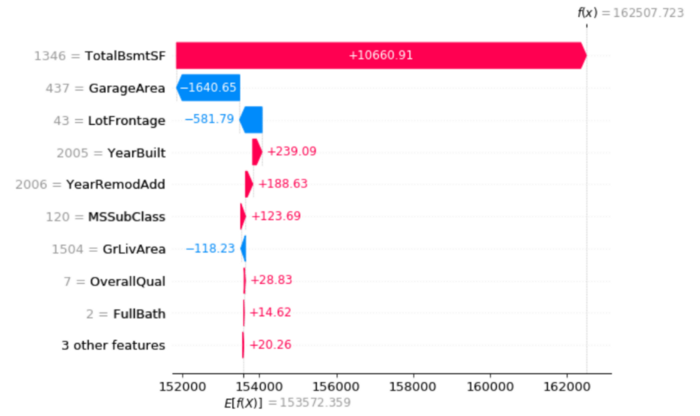
Вывод
Эта статья была учебным пособием для демонстрации как проектировать и создавать искусственные нейронные сети, глубокие и нет. Я шаг за шагом описал, что происходит внутри одного нейрона и, в более общем плане, внутри слоев.

