
Краткие сведения
В этой статье, используя науку о данных и Python, я объясню основные этапы использования классификации, начиная с анализа данных и заканчивая пониманием выходных данных модели.
Поскольку этот учебник может стать хорошей отправной точкой для начинающих, я буду использовать “набор данных Титаника” из знаменитого конкурса Kaggle, в котором вам предоставляются данные о пассажирах, и задача состоит в том, чтобы построить прогностическую модель, которая отвечает на вопрос: “Какие люди с большей вероятностью выживут?” (ссылка ниже).
Я представлю некоторый полезный код Python, который можно легко использовать в других подобных случаях (просто скопируйте, вставьте, запустите) и пройдитесь по каждой строке кода с комментариями, чтобы вы могли легко воспроизвести этот пример (ссылка на полный код ниже).
В частности, я пройду через:
- Настройка среды: импорт библиотек и чтение данных
- Анализ данных: понимание значения и прогностической силы переменных
- Разработка функций: извлечение функций из необработанных данных
- Предварительная обработка: разделение данных, обработка пропущенных значений, кодирование категориальных переменных, масштабирование
- Выбор функций: сохраняйте только наиболее релевантные переменные
- Проектирование модели: обучение, настройка гиперпараметров, проверка, тестирование
- Оценка эффективности: ознакомьтесь с показателями
- Объяснимость: понимание того, как модель дает результаты
Установка
Прежде всего, мне нужно импортировать следующие библиотеки.
## for data
import pandas as pd
import numpy as np
## for plotting
import matplotlib.pyplot as plt
import seaborn as sns
## for statistical tests
import scipy
import statsmodels.formula.api as smf
import statsmodels.api as sm
## for machine learning
from sklearn import model_selection, preprocessing, feature_selection, ensemble, linear_model, metrics, decomposition
## for explainer
from lime import lime_tabularЗатем я зачитаю данные в фрейм данных pandas.
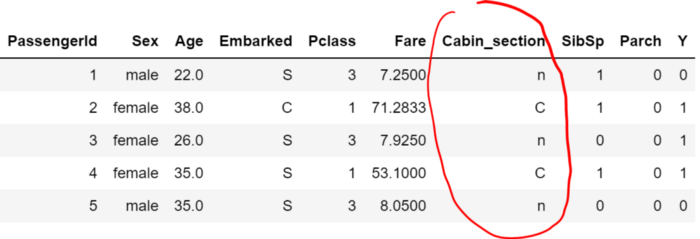
dtf = pd.read_csv('data_titanic.csv')
dtf.head()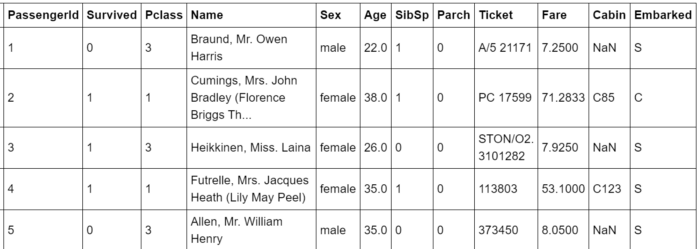
Подробную информацию о столбцах можно найти в предоставленной ссылке на набор данных.
Пожалуйста, обратите внимание, что каждая строка таблицы представляет конкретного пассажира (или наблюдение). Если вы работаете с другим набором данных, который не имеет подобной структуры, в которой каждая строка представляет наблюдение, вам необходимо обобщить данные и преобразовать их.
Теперь, когда все готово, я начну с анализа данных, затем выберу функции, построю модель машинного обучения и спрогнозирую.
Давайте начнем, хорошо?
Анализ Данных
В статистике, исследовательский анализ данных это процесс обобщения основных характеристик набора данных, чтобы понять, что данные могут рассказать нам помимо формального моделирования или задачи проверки гипотез.
Я всегда начинаю с обзора всего набора данных, в частности, я хочу знать, сколько категорический и численный переменные существуют и доля недостающие данные. Распознавание типа переменной иногда может быть сложным, потому что категории могут быть выражены в виде чисел (Survived c столбец состоит из 1 и 0). С этой целью я собираюсь написать простую функцию, которая сделает это за нас:
"'
Recognize whether a column is numerical or categorical.
:parameter
:param dtf: dataframe - input data
:param col: str - name of the column to analyze
:param max_cat: num - max number of unique values to recognize a column as categorical
:return
"cat" if the column is categorical or "num" otherwise
"'
def utils_recognize_type(dtf, col, max_cat=20):
if (dtf[col].dtype == "O") | (dtf[col].nunique() < max_cat):
return "cat"
else:
return "num"Эта функция очень полезна и может быть использована в нескольких случаях. Чтобы дать иллюстрацию, я построю график тепловая карта фрейма данных для визуализации типа столбцов и отсутствующих данных.
dic_cols = {col:utils_recognize_type(dtf, col, max_cat=20) for col in dtf.columns}
heatmap = dtf.isnull()
for k,v in dic_cols.items():
if v == "num":
heatmap[k] = heatmap[k].apply(lambda x: 0.5 if x is False else 1)
else:
heatmap[k] = heatmap[k].apply(lambda x: 0 if x is False else 1)
sns.heatmap(heatmap, cbar=False).set_title('Dataset Overview')
plt.show()
print("\033[1;37;40m Categerocial ", "\033[1;30;41m Numeric ", "\033[1;30;47m NaN ")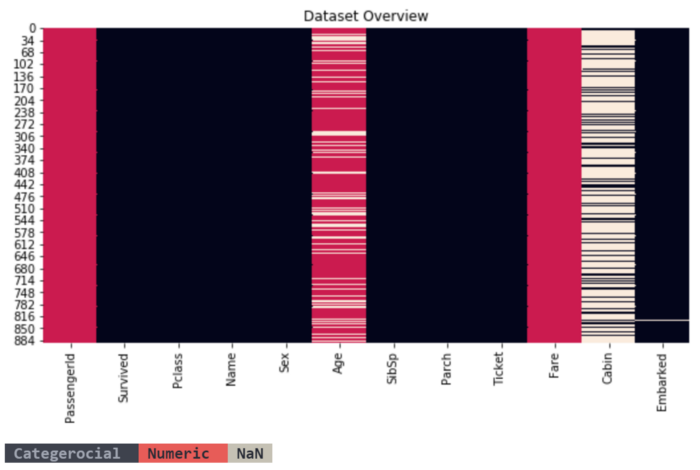
Всего 885 строк и 12 столбцов:
- каждая строка таблицы представляет конкретного пассажира (или наблюдение), идентифицированного Идентификатор пассажира, поэтому я установлю его в качестве индекса (или первичный ключ из таблицы для любителей SQL).
- Выживший это явление, которое мы хотим понять и предсказать (или целевую переменную), поэтому я переименую столбец как “Y”. Он содержит два класса: 1, если пассажир выжил, и 0 в противном случае, поэтому этот вариант использования является проблемой двоичной классификации.
- Возраст и Плата за проезд являются числовыми переменными, в то время как другие являются категориальными.
- Только Возраст и Кабина содержат недостающие данные.
dtf = dtf.set_index("PassengerId")
dtf = dtf.rename(columns={"Survived":"Y"})Я считаю, что визуализация-лучший инструмент для анализа данных, но вам нужно знать, какие графики больше подходят для различных типов переменных. Поэтому я предоставлю код для построения соответствующей визуализации для различных примеров.
Во-первых, давайте взглянем на одномерные распределения (распределение вероятностей только одной переменной). Участок в баре подходит для понимания частоты меток для одного категорический переменная. Например, давайте построим график целевой переменной:
y = "Y"
ax = dtf[y].value_counts().sort_values().plot(kind="barh")
totals= []
for i in ax.patches:
totals.append(i.get_width())
total = sum(totals)
for i in ax.patches:
ax.text(i.get_width()+.3, i.get_y()+.20,
str(round((i.get_width()/total)*100, 2))+'%',
fontsize=10, color='black')
ax.grid(axis="x")
plt.suptitle(y, fontsize=20)
plt.show()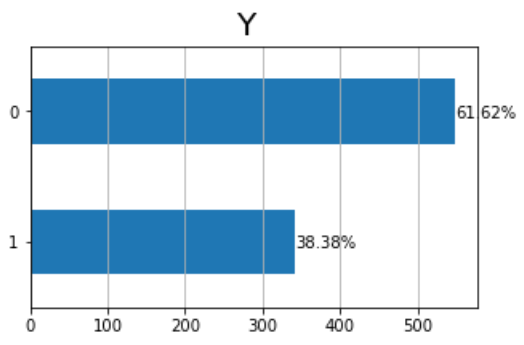
До 300 пассажиров выжили, а около 550-нет, другими словами, коэффициент выживаемости (или среднее население) составляет 38%.
Более того, а гистограмма идеально подходит для того, чтобы дать приблизительное представление о плотности базового распределения одного численный данные. Я рекомендую использовать участок коробки чтобы графически отобразить группы данных через их квартили. Давайте возьмем Например, возрастная переменная:
x = "Age"
fig, ax = plt.subplots(nrows=1, ncols=2, sharex=False, sharey=False)
fig.suptitle(x, fontsize=20)
### distribution
ax[0].title.set_text('distribution')
variable = dtf[x].fillna(dtf[x].mean())
breaks = np.quantile(variable, q=np.linspace(0, 1, 11))
variable = variable[ (variable > breaks[0]) & (variable <
breaks[10]) ]
sns.distplot(variable, hist=True, kde=True, kde_kws={"shade": True}, ax=ax[0])
des = dtf[x].describe()
ax[0].axvline(des["25%"], ls='--')
ax[0].axvline(des["mean"], ls='--')
ax[0].axvline(des["75%"], ls='--')
ax[0].grid(True)
des = round(des, 2).apply(lambda x: str(x))
box = '\n'.join(("min: "+des["min"], "25%: "+des["25%"], "mean: "+des["mean"], "75%: "+des["75%"], "max: "+des["max"]))
ax[0].text(0.95, 0.95, box, transform=ax[0].transAxes, fontsize=10, va='top', ha="right", bbox=dict(boxstyle='round', facecolor='white', alpha=1))
### boxplot
ax[1].title.set_text('outliers (log scale)')
tmp_dtf = pd.DataFrame(dtf[x])
tmp_dtf[x] = np.log(tmp_dtf[x])
tmp_dtf.boxplot(column=x, ax=ax[1])
plt.show()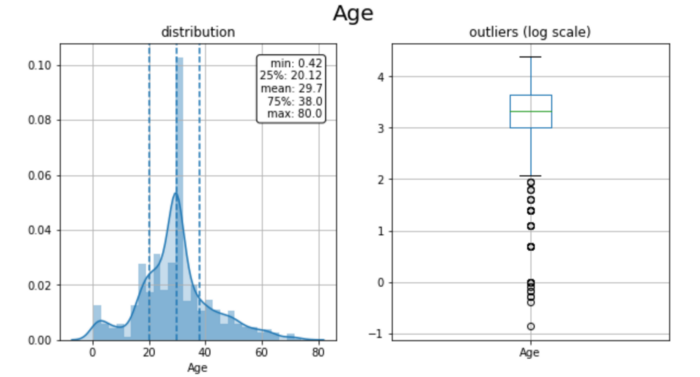
Пассажиры были в среднем довольно молоды: распределение смещено в левую сторону (среднее значение составляет 30 лет, а 75-й процентиль-38 лет). В сочетании с выбросами на графике коробки первый всплеск в левом хвосте говорит о том, что было значительное количество детей.
Я переведу анализ на следующий уровень и изучу двумерное распределение, чтобы понять, если Возраст обладает предсказательной способностью предсказывать Y Это было бы в случае категорический (Y) против численного (Возраст), поэтому я буду действовать так:
- разделите популяцию (весь набор наблюдений) на 2 выборки: доля пассажиров с Y = 1 (Выжил) и Y = 0 (Не Выжил).
- Постройте график и сравните плотности двух выборок, если распределения различны, то переменная является прогностической, поскольку две группы имеют разные закономерности.
- Сгруппируйте числовую переменную (Возраст) в ячейках (подвыборках) и постройте график состава каждой ячейки, если доля 1s одинакова во всех из них, то переменная не является прогностической.
- Постройте график и сравните прямоугольники двух выборок, чтобы определить различное поведение выбросов.
cat, num = "Y", "Age"
fig, ax = plt.subplots(nrows=1, ncols=3, sharex=False, sharey=False)
fig.suptitle(x+" vs "+y, fontsize=20)
### distribution
ax[0].title.set_text('density')
for i in dtf[cat].unique():
sns.distplot(dtf[dtf[cat]==i][num], hist=False, label=i, ax=ax[0])
ax[0].grid(True)
### stacked
ax[1].title.set_text('bins')
breaks = np.quantile(dtf[num], q=np.linspace(0,1,11))
tmp = dtf.groupby([cat, pd.cut(dtf[num], breaks, duplicates='drop')]).size().unstack().T
tmp = tmp[dtf[cat].unique()]
tmp["tot"] = tmp.sum(axis=1)
for col in tmp.drop("tot", axis=1).columns:
tmp[col] = tmp[col] / tmp["tot"]
tmp.drop("tot", axis=1).plot(kind='bar', stacked=True, ax=ax[1], legend=False, grid=True)
### boxplot
ax[2].title.set_text('outliers')
sns.catplot(x=cat, y=num, data=dtf, kind="box", ax=ax[2])
ax[2].grid(True)
plt.show()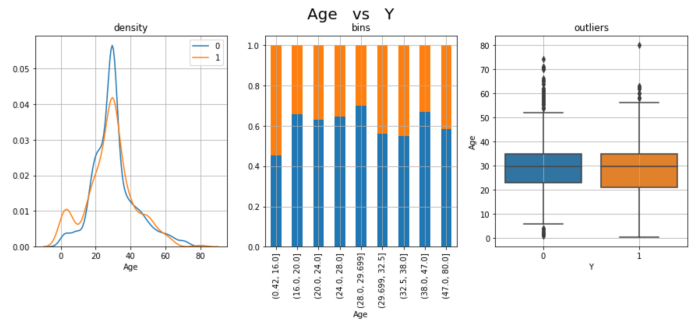
Эти 3 графика-просто разные точки зрения на вывод о том, что Возраст является прогностическим. Коэффициент выживаемости выше у более молодых пассажиров: в левом хвосте распределения 1s наблюдается всплеск, и в первом бункере (0-16 лет) содержится самый высокий процент выживших пассажиров.
Когда вас не убеждает “интуиция глаза”, вы всегда можете прибегнуть к старой доброй статистике и провести тест. В данном случае категорического (Y) против численного (Возраст), я бы использовал односторонний тест ANOVA. В принципе, он проверяет, существенно ли отличаются средние значения двух или более независимых выборок, поэтому, если значение p достаточно мало
cat, num = "Y", "Age"
model = smf.ols(num+' ~ '+cat, data=dtf).fit()
table = sm.stats.anova_lm(model)
p = table["PR(>F)"][0]
coeff, p = None, round(p, 3)
conclusion = "Correlated" if p < 0.05 else "Non-Correlated"
print("Anova F: the variables are", conclusion, "(p-value: "+str(p)+")")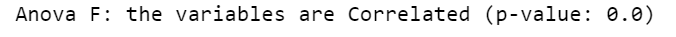
Очевидно, возраст пассажиров способствовал их выживанию. Это имеет смысл, поскольку жизни женщин и детей должны были быть спасены в первую очередь в опасной для жизни ситуации, как правило, при оставлении судна, когда ресурсы выживания, такие как спасательные шлюпки, были ограничены (“женщины и дети в первую очередь” код»).
Чтобы проверить обоснованность этого первого вывода, мне придется проанализировать поведение Секс переменная по отношению к целевой переменной. Это случай, когда категорический (Y) против категорического (Секс), поэтому я построю 2 столбчатых графика, один с количеством 1 и 0 среди двух категорий Секс (мужчина и женщина) и другой с процентами.
x, y = "Sex", "Y"
fig, ax = plt.subplots(nrows=1, ncols=2, sharex=False, sharey=False)
fig.suptitle(x+" vs "+y, fontsize=20)
### count
ax[0].title.set_text('count')
order = dtf.groupby(x)[y].count().index.tolist()
sns.catplot(x=x, hue=y, data=dtf, kind='count', order=order, ax=ax[0])
ax[0].grid(True)
### percentage
ax[1].title.set_text('percentage')
a = dtf.groupby(x)[y].count().reset_index()
a = a.rename(columns={y:"tot"})
b = dtf.groupby([x,y])[y].count()
b = b.rename(columns={y:0}).reset_index()
b = b.merge(a, how="left")
b["%"] = b[0] / b["tot"] *100
sns.barplot(x=x, y="%", hue=y, data=b,
ax=ax[1]).get_legend().remove()
ax[1].grid(True)
plt.show()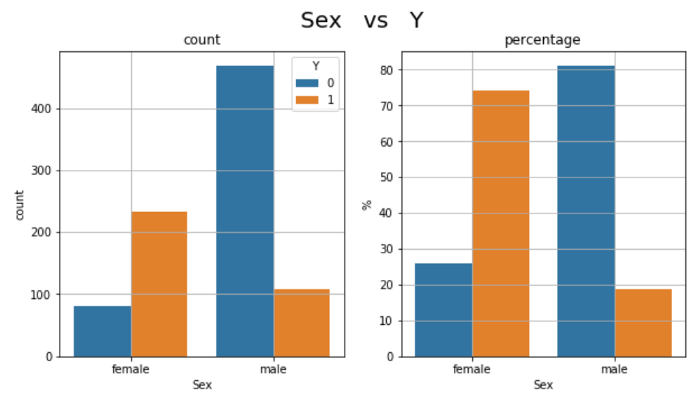
Более 200 пассажиров-женщин (75% от общего числа женщин на борту) и около 100 пассажиров-мужчин (менее 20%) выжили. Другими словами, среди женщин выживаемость составляет 75%, а среди мужчин-20%, поэтому Секс является прогностическим. Более того, это подтверждает, что они уделяли приоритетное внимание женщинам и детям.
Как и раньше, мы можем проверить корреляцию этих 2 переменных. Поскольку они оба категоричны, я бы использовал C тест hi-Square: предполагая, что две переменные независимы (нулевая гипотеза), он проверяет, равномерно ли распределены значения таблицы непредвиденных обстоятельств для этих переменных. Если значение p достаточно мало ( Можно рассчитать C рамера V t шляпа — это мера корреляции, которая следует из этого теста, которая является симметричной (как и традиционная корреляция Пирсона) и колеблется от 0 до 1 (в отличие от традиционной корреляции Пирсона, отрицательных значений нет).
x, y = "Sex", "Y"
cont_table = pd.crosstab(index=dtf[x], columns=dtf[y])
chi2_test = scipy.stats.chi2_contingency(cont_table)
chi2, p = chi2_test[0], chi2_test[1]
n = cont_table.sum().sum()
phi2 = chi2/n
r,k = cont_table.shape
phi2corr = max(0, phi2-((k-1)*(r-1))/(n-1))
rcorr = r-((r-1)**2)/(n-1)
kcorr = k-((k-1)**2)/(n-1)
coeff = np.sqrt(phi2corr/min((kcorr-1), (rcorr-1)))
coeff, p = round(coeff, 3), round(p, 3)
conclusion = "Significant" if p < 0.05 else "Non-Significant"
print("Cramer Correlation:", coeff, conclusion, "(p-value:"+str(p)+")")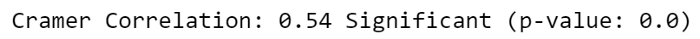
Возраст и Секс приведены примеры прогностических функций, но не все столбцы в наборе данных похожи на это. Например, Кабина кажется, это бесполезная переменная поскольку он не предоставляет никакой полезной информации, в нем слишком много отсутствующих значений и категорий.
Такой анализ следует проводить для каждой переменной в наборе данных, чтобы решить, что следует сохранить в качестве потенциальной функции, а что можно удалить, поскольку оно не является прогнозирующим (см. ссылку на полный код).
Разработка функций
Пришло время создавать новые функции из необработанных данных, используя знания предметной области. Я приведу один пример: я попытаюсь создать полезную функцию, извлекая информацию из Кабина «. Я предполагаю, что буква в начале каждого номера каюты (т. Е. “B96”) указывает на какой-то участок, возможно, рядом со спасательными шлюпками были какие-то удачные участки. Я обобщу наблюдения в кластерах, выделив раздел каждой кабины:
## Create new column
dtf["Cabin_section"] = dtf["Cabin"].apply(lambda x: str(x)[0])
## Plot contingency table
cont_table = pd.crosstab(index=dtf["Cabin_section"],
columns=dtf["Pclass"], values=dtf["Y"], aggfunc="sum")
sns.heatmap(cont_table, annot=True, cmap="YlGnBu", fmt='.0f',
linewidths=.5).set_title(
'Cabin_section vs Pclass (filter: Y)' )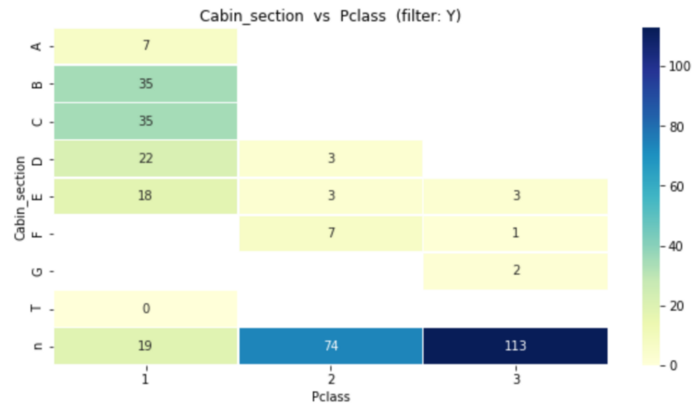
Этот график показывает, как выжившие распределяются по секциям и классам кают (7 выживших находятся в секции A, 35 в B,…). Большинство разделов отнесены к 1-му и 2-му классам, в то время как большинство отсутствующих разделов “н”:
Предварительная обработка
Предварительная обработка данных-это этап подготовки исходных данных, чтобы сделать их пригодными для модели машинного обучения. В частности:
- каждое наблюдение должно быть представлено одной строкой, другими словами, у вас не может быть двух строк, описывающих одного и того же пассажира, потому что они будут обрабатываться моделью отдельно (набор данных уже находится в такой форме, поэтому ✅). Кроме того, каждый столбец должен быть функцией, поэтому вы не должны использовать PassengerId в качестве предиктора, поэтому такая таблица называется “матрица функций”.
- Набор данных должен быть разделенные по крайней мере, в два набора: модель должна быть обучена на значительной части вашего набора данных (так называемый “набор обучающих данных”) и протестирована на меньшем наборе (“набор тестов”).
- Пропущенные значения следует чем-то заменить, иначе ваша модель может сойти с ума.
- Категориальные данные должно быть закодировано, что означает преобразование меток в целые числа, потому что машинное обучение ожидает чисел, а не строк.
- Это хорошая практика, чтобы масштаб данные, это помогает нормализовать данные в определенном диапазоне и ускорить вычисления в алгоритме.
Хорошо, давайте начнем с разделения набора данных. При разделении данных на наборы поездов и тестов вы должны следовать 1 основному правилу: строки в наборе поездов также не должны появляться в наборе тестов. Это происходит потому, что модель видит целевые значения во время обучения и использует их для понимания явления. Другими словами, модель уже знает правильный ответ для обучающих наблюдений, и тестирование ее на них было бы похоже на мошенничество. Я видел много людей, предлагающих свои модели машинного обучения, утверждающих, что точность составляет 99,99%, которые на самом деле игнорировали это правило. К счастью, Scikit-учитесь посылка знает, что:
## split data
dtf_train, dtf_test = model_selection.train_test_split(dtf,
test_size=0.3)
## print info
print("X_train shape:", dtf_train.drop("Y",axis=1).shape, "| X_test shape:", dtf_test.drop("Y",axis=1).shape)
print("y_train mean:", round(np.mean(dtf_train["Y"]),2), "| y_test mean:", round(np.mean(dtf_test["Y"]),2))
print(dtf_train.shape[1], "features:", dtf_train.drop("Y",axis=1).columns.to_list())
Следующий шаг: Возраст столбец содержит некоторые недостающие данные (19%), с которыми необходимо разобраться. На практике вы можете заменить отсутствующие данные определенным значением, например 9999, которое отслеживает недостающую информацию, но изменяет распределение переменных. В качестве альтернативы вы можете использовать среднее значение столбца, как я собираюсь сделать. Я хотел бы подчеркнуть, что с точки зрения машинного обучения правильно сначала разделить на обучение и тестирование, а затем заменить нан украины только со средним значением тренировочного набора.
dtf_train["Age"] = dtf_train["Age"].fillna(dtf_train["Age"].mean())Есть еще некоторые категориальные данные это должно быть закодировано. Двумя наиболее распространенными кодерами являются Кодировщик меток (каждая уникальная метка сопоставляется целому числу) и кодировщик с одним горячим кодом (каждая метка сопоставляется двоичному вектору). Первый из них подходит только для данных с ординарностью. Если применить к столбцу без ординарности, например Секс, это повернуло бы вектор [мэль, женский, женский, мужской, …] в [1, 2, 2, 1, …] и у нас было бы это женское > мужское и в среднем 1,5, что не имеет смысла. С другой стороны, Один Горячий кодировщик преобразует предыдущий пример в два фиктивные переменные (дихотомические количественные переменные): Male [1, 0, 0, 1, …] и Fem эль [0, 1, 1, 0, …]. Преимущество состоит в том, что результат является двоичным, а не порядковым, и что все находится в ортогональном векторном пространстве, но функции с высокой мощностью могут привести к проблеме размерности. Я буду использовать метод одного горячего кодирования, преобразуя 1 категориальный столбец с n уникальными значениями в n-1 манекенов. Давайте закодируем Секс как пример:
## create dummy
dummy = pd.get_dummies(dtf_train["Sex"],
prefix="Sex",drop_first=True)
dtf_train= pd.concat([dtf_train, dummy], axis=1)
print( dtf_train.filter(like="Sex", axis=1).head() )
## drop the original categorical column
dtf = dtf_train.drop("Sex", axis=1)
И последнее, но не менее важное: я собираюсь масштабируйте функции. Существует несколько различных способов сделать это, я приведу только наиболее часто используемые из них: стандартный масштабатор и масштабатор MinMax. Первый предполагает, что данные распределены нормально, и масштабирует их таким образом, что распределение сосредоточено вокруг 0 со стандартным отклонением 1. Однако выбросы оказывают влияние при вычислении эмпирического среднего и стандартного отклонения, которые сужают диапазон значений признаков, поэтому этот масштабировщик не может гарантировать сбалансированные масштабы признаков при наличии выбросов. С другой стороны, масштабатор MinMax масштабирует набор данных таким образом, чтобы все значения объектов находились в одном диапазоне (0-1). Он меньше подвержен выбросам, но сжимает все выбросы в узком диапазоне. Поскольку мои данные обычно не распределяются, я воспользуюсь MinMax-масштабатором:
scaler = preprocessing.MinMaxScaler(feature_range=(0,1))
X = scaler.fit_transform(dtf_train.drop("Y", axis=1))
dtf_scaled= pd.DataFrame(X, columns=dtf_train.drop("Y", axis=1).columns, index=dtf_train.index)
dtf_scaled["Y"] = dtf_train["Y"]
dtf_scaled.head()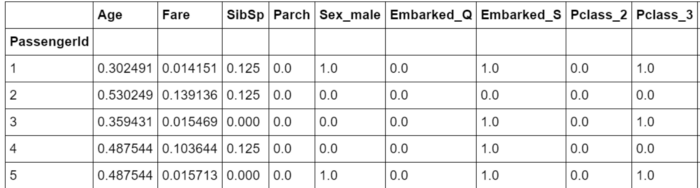
Выбор функций
Выбор функций — это процесс выбора подмножества соответствующих переменных для построения модели машинного обучения. Это облегчает интерпретацию модели и уменьшает перенапряжение (когда модель слишком сильно адаптируется к данным обучения и плохо работает за пределами набора тренировок).
Я уже сделал первый “ручной” выбор функций во время анализа данных, исключив ненужные столбцы. Теперь все будет немного по-другому, потому что мы предполагаем, что все функции в матрице релевантны, и мы хотим отбросить ненужные. Когда функция не нужна? Что ж, ответ прост: когда есть лучший эквивалент или тот, который выполняет ту же работу, но лучше.
Я объясню на примере: Pclass сильно коррелирует с Cabin_section, потому что, как мы видели ранее, некоторые разделы были расположены в 1-м классе, а другие-во 2-м. Давайте вычислим корреляционную матрицу, чтобы увидеть ее:
corr_matrix = dtf.copy()
for col in corr_matrix.columns:
if corr_matrix[col].dtype == "O":
corr_matrix[col] = corr_matrix[col].factorize(sort=True)[0]
corr_matrix = corr_matrix.corr(method="pearson")
sns.heatmap(corr_matrix, vmin=-1., vmax=1., annot=True, fmt='.2f', cmap="YlGnBu", cbar=True, linewidths=0.5)
plt.title("pearson correlation")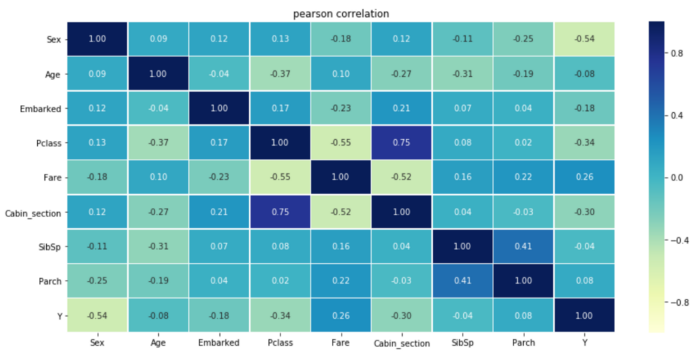
Один из Класс P и Cabin_section может бытьненужный, и мы можем решить отказаться от него и оставить наиболее полезный (т. Е. тот, у которого наименьшее значение p или тот, который больше всего снижает энтропию).
Я покажу два разных способа автоматического выбора функций: сначала я буду использовать метод регуляризациии сравните его с тестом ANOVA, уже упомянутым ранее, затем я покажу, как получить важность функций с помощью методов ансамбля.
Регуляризация ЛАССО это метод регрессионного анализа, который выполняет как выбор переменных, так и регуляризацию для повышения точности и интерпретируемости.
X = dtf_train.drop("Y", axis=1).values
y = dtf_train["Y"].values
feature_names = dtf_train.drop("Y", axis=1).columns
##
selector = feature_selection.SelectKBest(score_func=
feature_selection.f_classif, k=10).fit(X,y)
anova_selected_features = feature_names[selector.get_support()]
##
selector = feature_selection.SelectFromModel(estimator=
linear_model.LogisticRegression(C=1, penalty="l1",
solver='liblinear'), max_features=10).fit(X,y)
lasso_selected_features = feature_names[selector.get_support()]
## Plot
dtf_features = pd.DataFrame({"features":feature_names})
dtf_features["anova"] = dtf_features["features"].apply(lambda x: "anova" if x in anova_selected_features else "")
dtf_features["num1"] = dtf_features["features"].apply(lambda x: 1 if x in anova_selected_features else 0)
dtf_features["lasso"] = dtf_features["features"].apply(lambda x: "lasso" if x in lasso_selected_features else "")
dtf_features["num2"] = dtf_features["features"].apply(lambda x: 1 if x in lasso_selected_features else 0)
dtf_features["method"] = dtf_features[["anova","lasso"]].apply(lambda x: (x[0]+" "+x[1]).strip(), axis=1)
dtf_features["selection"] = dtf_features["num1"] + dtf_features["num2"]
sns.barplot(y="features", x="selection", hue="method", data=dtf_features.sort_values("selection", ascending=False), dodge=False)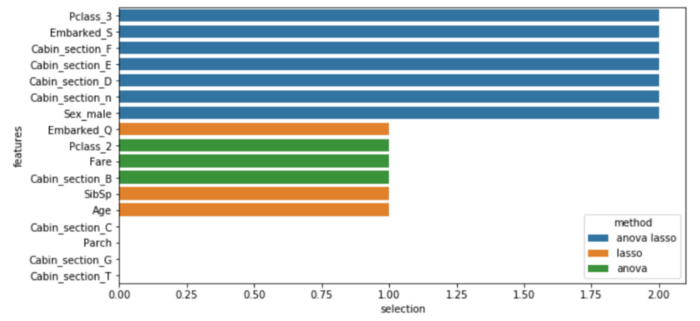
Синие объекты выбираются как ANOVA, так и LASSO, остальные выбираются только одним из двух методов.
Случайный лес — это метод ансамбля, состоящий из нескольких деревьев решений, в которых каждый узел является условием для одного объекта, предназначенный для разделения набора данных на два, чтобы одинаковые значения ответов попадали в один и тот же набор. Важность объектов вычисляется по тому, насколько каждый объект уменьшает энтропию в дереве.
X = dtf_train.drop("Y", axis=1).values
y = dtf_train["Y"].values
feature_names = dtf_train.drop("Y", axis=1).columns.tolist()
##
model = ensemble.RandomForestClassifier(n_estimators=100,
criterion="entropy", random_state=0)
model.fit(X,y)
importances = model.feature_importances_
## Put in a pandas dtf
dtf_importances = pd.DataFrame({"IMPORTANCE":importances,
"VARIABLE":feature_names}).sort_values("IMPORTANCE",
ascending=False)
dtf_importances['cumsum'] =
dtf_importances['IMPORTANCE'].cumsum(axis=0)
dtf_importances = dtf_importances.set_index("VARIABLE")
## Plot
fig, ax = plt.subplots(nrows=1, ncols=2, sharex=False, sharey=False)
fig.suptitle("Features Importance", fontsize=20)
ax[0].title.set_text('variables')
dtf_importances[["IMPORTANCE"]].sort_values(by="IMPORTANCE").plot(
kind="barh", legend=False, ax=ax[0]).grid(axis="x")
ax[0].set(ylabel="")
ax[1].title.set_text('cumulative')
dtf_importances[["cumsum"]].plot(kind="line", linewidth=4,
legend=False, ax=ax[1])
ax[1].set(xlabel="", xticks=np.arange(len(dtf_importances)),
xticklabels=dtf_importances.index)
plt.xticks(rotation=70)
plt.grid(axis='both')
plt.show()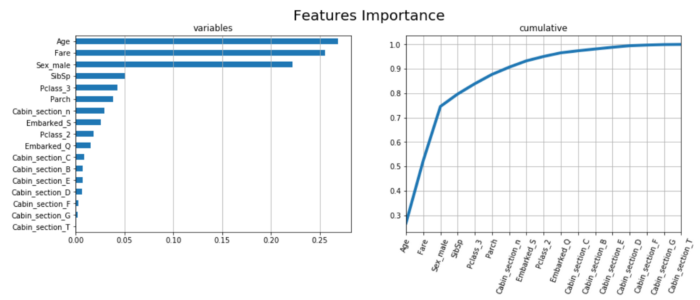
Действительно интересно, что Возраст и стоимость проезда, которые на этот раз являются наиболее важными функциями, раньше не были главными функциями, и что, напротив, Cabin_section E, F и D здесь не кажутся действительно полезными.
Лично я всегда стараюсь использовать как можно меньше функций, поэтому здесь я выбираю следующие и приступаю к проектированию, обучению, тестированию и оценке модели машинного обучения:
X_names = ["Age", "Fare", "Sex_male", "SibSp", "Pclass_3", "Parch",
"Cabin_section_n", "Embarked_S", "Pclass_2", "Cabin_section_F", "Cabin_section_E", "Cabin_section_D"]
X_train = dtf_train[X_names].values
y_train = dtf_train["Y"].values
X_test = dtf_test[X_names].values
y_test = dtf_test["Y"].valuesПожалуйста, обратите внимание, что перед использованием тестовых данных для прогнозирования вы должны предварительно обработать их так же, как мы это сделали для данных о поездах.
Дизайн Модели
Наконец, пришло время построить модель машинного обучения. Во-первых, нам нужно выбрать алгоритм, который способен на основе обучающих данных научиться распознавать два класса целевой переменной, минимизируя некоторую функцию ошибок.
Я предлагаю всегда пробовать алгоритм повышения градиента (например, XGBoost). Это метод машинного обучения, который создает модель прогнозирования в виде ансамбля слабых моделей прогнозирования, обычно деревьев решений. По сути, это похоже на Случайный лес с той разницей, что каждое дерево подгоняется по ошибке предыдущего.

Существует множество гиперпараметров, и нет общего правила о том, что лучше, поэтому вам просто нужно найти правильную комбинацию, которая лучше соответствует вашим данным. Вы можете выполнить различные попытки вручную или позволить компьютеру выполнить эту утомительную работу с помощью поиска по сетке (пробует все возможные комбинации, но требует времени) или с помощью случайного поиска (пробует случайным образом фиксированное количество итераций). Я попробую провести рандонсеарч для своего настройка гиперпараметров: машина повторит n раз (1000) через обучающие данные, чтобы найти комбинацию параметров (указанных в приведенном ниже коде), которая максимизирует функцию оценки, используемую в качестве KPI (точность, отношение числа правильных прогнозов к общему числу входных выборок).:
## call model
model = ensemble.GradientBoostingClassifier()
## define hyperparameters combinations to try
param_dic = {'learning_rate':[0.15,0.1,0.05,0.01,0.005,0.001], #weighting factor for the corrections by new trees when added to the model
'n_estimators':[100,250,500,750,1000,1250,1500,1750], #number of trees added to the model
'max_depth':[2,3,4,5,6,7], #maximum depth of the tree
'min_samples_split':[2,4,6,8,10,20,40,60,100], #sets the minimum number of samples to split
'min_samples_leaf':[1,3,5,7,9], #the minimum number of samples to form a leaf
'max_features':[2,3,4,5,6,7], #square root of features is usually a good starting point
':[0.7,0.75,0.8,0.85,0.9,0.95,1]} #the fraction of samples to be used for fitting the individual base learners. Values lower than 1 generally lead to a reduction of variance and an increase in bias.
## random search
random_search = model_selection.RandomizedSearchCV(model,
param_distributions=param_dic, n_iter=1000,
scoring="accuracy").fit(X_train, y_train)
print("Best Model parameters:", random_search.best_params_)
print("Best Model mean accuracy:", random_search.best_score_)
model = random_search.best_estimator_
Круто, это лучшая модель со средней точностью 0,85, так что, вероятно, 85% прогнозов в тестовом наборе будут правильными.
Мы также можем проверить эту модель с помощью k-кратной перекрестной проверки, процедуры, которая заключается в разделении данных k раз на обучающие и проверочные наборы, и для каждого разделения модель обучается и тестируется. Он используется для проверки того, насколько хорошо модель может обучаться некоторым данным и прогнозировать невидимые данные.
Я хотел бы уточнить, что я называю набором проверки набор примеров, используемых для настройки гиперпараметров классификатора, извлеченных из обучающих данных. С другой стороны, набор тестов-это моделирование того, как модель будет работать в производстве, когда ее попросят предсказать наблюдения, которых никогда раньше не видели.
Обычно для каждой складки строится кривая ROC, график, который иллюстрирует, как изменяется способность двоичного классификатора при изменении его порога дискриминации. Он создается путем построения графика истинной положительной скорости (правильно предсказанной 1 с) против ложной положительной скорости (предсказанной 1 с, которая на самом деле равна 0 с) при различных настройках порога. AUC (область под кривой ROC) указывает вероятность того, что классификатор ранжирует случайно выбранное положительное наблюдение (Y=1) выше, чем случайно выбранное отрицательное (Y=0).
Теперь я покажу пример с 10 складками (k=10):
cv = model_selection.StratifiedKFold(n_splits=10, shuffle=True)
tprs, aucs = [], []
mean_fpr = np.linspace(0,1,100)
fig = plt.figure()
i = 1
for train, test in cv.split(X_train, y_train):
prediction = model.fit(X_train[train],
y_train[train]).predict_proba(X_train[test])
fpr, tpr, t = metrics.roc_curve(y_train[test], prediction[:, 1])
tprs.append(scipy.interp(mean_fpr, fpr, tpr))
roc_auc = metrics.auc(fpr, tpr)
aucs.append(roc_auc)
plt.plot(fpr, tpr, lw=2, alpha=0.3, label='ROC fold %d (AUC =
%0.2f)' % (i, roc_auc))
i = i+1
plt.plot([0,1], [0,1], linestyle='--', lw=2, color='black')
mean_tpr = np.mean(tprs, axis=0)
mean_auc = metrics.auc(mean_fpr, mean_tpr)
plt.plot(mean_fpr, mean_tpr, color='blue', label=r'Mean ROC (AUC =
%0.2f )' % (mean_auc), lw=2, alpha=1)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('K-Fold Validation')
plt.legend(loc="lower right")
plt.show()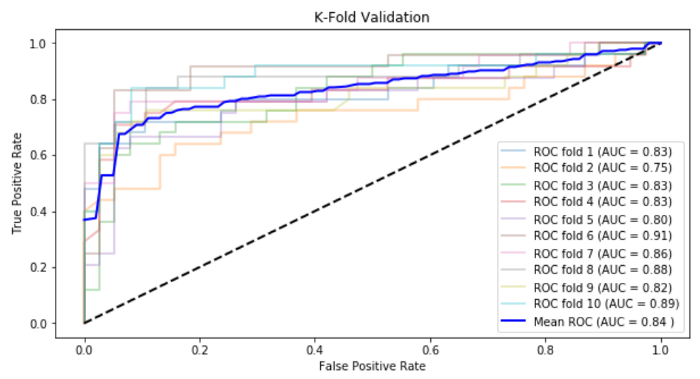
Согласно этой проверке, мы должны ожидать оценки AUC около 0,84 при составлении прогнозов по тесту.
Для целей этого урока я бы сказал, что производительность отличная, и мы можем продолжить работу с моделью, выбранной методом случайного поиска. Как только выбрана правильная модель, ее можно обучить на всем наборе поездов, а затем протестировать на тестовом наборе.
## train
model.fit(X_train, y_train)
## test
predicted_prob = model.predict_proba(X_test)[:,1]
predicted = model.predict(X_test)В приведенном выше коде я сделал два вида предсказаний: первое-вероятность того, что наблюдение равно 1, а второе-предсказание метки (1 или 0). Чтобы получить последнее, вам нужно определить порог вероятности, для которого наблюдение может рассматриваться как 1, я использовал порог по умолчанию 0,5.
Оценка
Момент истины, мы вот-вот увидим, стоит ли вся эта тяжелая работа того. Весь смысл в том, чтобы изучить, сколько правильных прогнозов и типов ошибок делает модель.
Я буду оценивать модель, используя следующие общие показатели: Точность, AUC, Точность и отзывчивость. Я уже упоминал о первых двух, но я считаю, что остальные гораздо важнее. Точность-это доля 1 (или 0), которую модель правильно предсказала среди всех предсказанных 1 (или 0), поэтому ее можно рассматривать как своего рода уровень достоверности при прогнозировании 1 (или 0). Напомним, что часть 1 (или 0), которую модель правильно предсказала среди всех 1 (или 0) в наборе тестов, в основном это истинная скорость 1. Сочетая точность и отзыв с армоническим значением, вы получаете оценку F1.
Давайте посмотрим, как модель справилась с тестовым набором:
## Accuray e AUC
accuracy = metrics.accuracy_score(y_test, predicted)
auc = metrics.roc_auc_score(y_test, predicted_prob)
print("Accuracy (overall correct predictions):", round(accuracy,2))
print("Auc:", round(auc,2))
## Precision e Recall
recall = metrics.recall_score(y_test, predicted)
precision = metrics.precision_score(y_test, predicted)
print("Recall (all 1s predicted right):", round(recall,2))
print("Precision (confidence when predicting a 1):", round(precision,2))
print("Detail:")
print(metrics.classification_report(y_test, predicted, target_names=[str(i) for i in np.unique(y_test)]))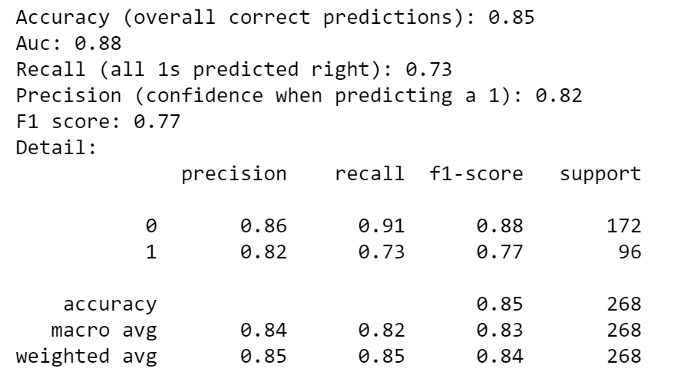
Как и ожидалось, общая точность модели составляет около 85%. Он правильно предсказал 71% 1 с точностью 84% и 92% 0 с точностью 85%. Чтобы лучше понять эти показатели, я разберу результаты в матрицу путаницы:
classes = np.unique(y_test)
fig, ax = plt.subplots()
cm = metrics.confusion_matrix(y_test, predicted, labels=classes)
sns.heatmap(cm, annot=True, fmt='d', cmap=plt.cm.Blues, cbar=False)
ax.set(xlabel="Pred", ylabel="True", title="Confusion matrix")
ax.set_yticklabels(labels=classes, rotation=0)
plt.show()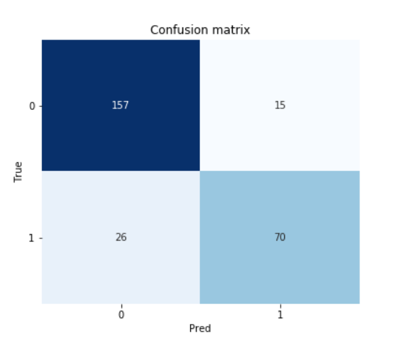
Мы видим, что модель предсказала 85 (70+15) 1, из которых 70 являются истинными положительными и 15 являются ложными положительными, поэтому она имеет точность 70/85 = 0,82 при прогнозировании 1. С другой стороны, модель получила право на 70 1 из всех 96 (70+26) 1 в тестовом наборе, поэтому ее отзыв составляет 70/96 = 0,73.
Выбор порогового значения 0,5 для определения того, является ли прогноз 1 или 0, привел к этому результату. Было бы по-другому с другим? Определенно да, но нет порога, который бы давал наивысший балл как по точности, так и по отзыву, выбор порога означает компромисс между этими двумя показателями. Я покажу, что я имею в виду, построив кривую ROC и кривую точного отзыва результата теста:
classes = np.unique(y_test)
fig, ax = plt.subplots(nrows=1, ncols=2)
## plot ROC curve
fpr, tpr, thresholds = metrics.roc_curve(y_test, predicted_prob)
roc_auc = metrics.auc(fpr, tpr)
ax[0].plot(fpr, tpr, color='darkorange', lw=3, label='area = %0.2f' % roc_auc)
ax[0].plot([0,1], [0,1], color='navy', lw=3, linestyle='--')
ax[0].hlines(y=recall, xmin=0, xmax=1-cm[0,0]/(cm[0,0]+cm[0,1]), color='red', linestyle='--', alpha=0.7, label="chosen threshold")
ax[0].vlines(x=1-cm[0,0]/(cm[0,0]+cm[0,1]), ymin=0, ymax=recall, color='red', linestyle='--', alpha=0.7)
ax[0].set(xlabel='False Positive Rate', ylabel="True Positive Rate (Recall)", title="Receiver operating characteristic")
ax.legend(loc="lower right")
ax.grid(True)
## annotate ROC thresholds
thres_in_plot = []
for i,t in enumerate(thresholds):
t = np.round(t,1)
if t not in thres_in_plot:
ax.annotate(t, xy=(fpr[i],tpr[i]), xytext=(fpr[i],tpr[i]),
textcoords='offset points', ha='left', va='bottom')
thres_in_plot.append(t)
else:
next
## plot P-R curve
precisions, recalls, thresholds = metrics.precision_recall_curve(y_test, predicted_prob)
roc_auc = metrics.auc(recalls, precisions)
ax[1].plot(recalls, precisions, color='darkorange', lw=3, label='area = %0.2f' % roc_auc)
ax[1].plot([0,1], [(cm[1,0]+cm[1,0])/len(y_test), (cm[1,0]+cm[1,0])/len(y_test)], linestyle='--', color='navy', lw=3)
ax[1].hlines(y=precision, xmin=0, xmax=recall, color='red', linestyle='--', alpha=0.7, label="chosen threshold")
ax[1].vlines(x=recall, ymin=0, ymax=precision, color='red', linestyle='--', alpha=0.7)
ax[1].set(xlabel='Recall', ylabel="Precision", title="Precision-Recall curve")
ax[1].legend(loc="lower left")
ax[1].grid(True)
## annotate P-R thresholds
thres_in_plot = []
for i,t in enumerate(thresholds):
t = np.round(t,1)
if t not in thres_in_plot:
ax.annotate(np.round(t,1), xy=(recalls[i],precisions[i]),
xytext=(recalls[i],precisions[i]),
textcoords='offset points', ha='left', va='bottom')
thres_in_plot.append(t)
else:
next
plt.show()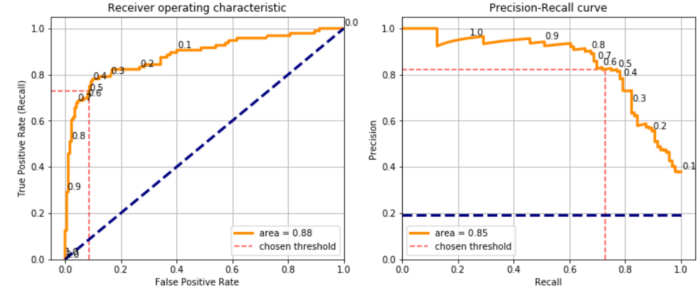
Каждая точка этих кривых представляет собой матрицу путаницы, полученную с различным порогом (цифры, напечатанные на кривых). Я мог бы использовать пороговое значение 0,1 и получить отзыв 0,9, что означает, что модель правильно предсказала бы 90% 1, но точность снизилась бы до 0,4, что означает, что модель предсказала бы много ложных срабатываний. Таким образом, это действительно зависит от типа варианта использования и, в частности, от того, имеет ли ложноположительный результат более высокую стоимость ложноотрицательного.
Когда набор данных сбалансирован, а показатели не заданы заинтересованными сторонами проекта, я обычно выбираю пороговое значение, которое максимизирует оценку F1. Вот как:
## calculate scores for different thresholds
dic_scores = {'accuracy':[], 'precision':[], 'recall':[], 'f1':[]}
XX_train, XX_test, yy_train, yy_test = model_selection.train_test_split(X_train, y_train, test_size=0.2)
predicted_prob = model.fit(XX_train, yy_train).predict_proba(XX_test)[:,1]
thresholds = []
for threshold in np.arange(0.1, 1, step=0.1):
predicted = (predicted_prob > threshold)
thresholds.append(threshold)
dic_scores["accuracy"].append(metrics.accuracy_score(yy_test, predicted))
dic_scores["precision"].append(metrics.precision_score(yy_test, predicted))
dic_scores["recall"].append(metrics.recall_score(yy_test, predicted))
dic_scores["f1"].append(metrics.f1_score(yy_test, predicted))
## plot
dtf_scores = pd.DataFrame(dic_scores).set_index(pd.Index(thresholds))
dtf_scores.plot(ax=ax, title="Threshold Selection")
plt.show()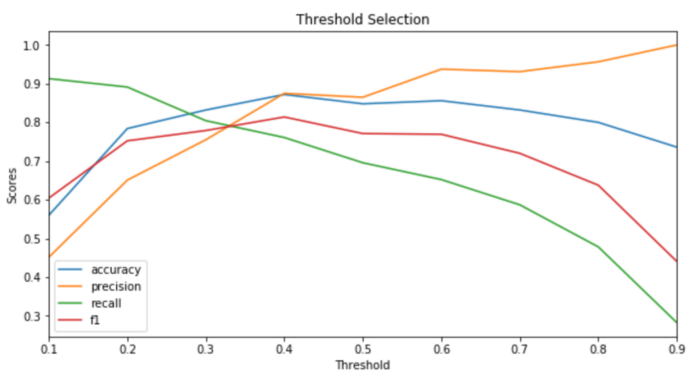
Прежде чем перейти к последнему разделу этого длинного урока, я хотел бы сказать, что мы пока не можем сказать, хороша или плоха модель. Точность составляет 0,85, она высока? По сравнению с чем? Вам нужна базовая линия для сравнения вашей модели. Возможно, проект, над которым вы работаете, заключается в создании новой модели взамен старой, которую можно использовать в качестве базовой, или вы можете обучать разные модели машинного обучения на одном и том же наборе обучающих программ и сравнивать производительность набора тестов.
Объяснимость
Вы проанализировали и поняли данные, вы обучили модель и протестировали ее, вы даже удовлетворены производительностью. Ты думаешь, что с тобой все кончено? Неправильный. Высока вероятность того, что заинтересованная сторона проекта не заботится о ваших показателях и не понимает ваш алгоритм, поэтому вы должны показать, что ваша модель машинного обучения не является черным ящиком.
Пакет Lime может помочь нам создать объяснитель. Для иллюстрации я возьму случайное наблюдение из набора тестов и посмотрю, что предсказывает модель:
print("True:", y_test[4], "--> Pred:", predicted[4], "| Prob:", np.max(predicted_prob[4]))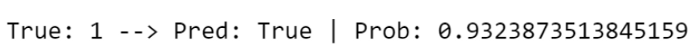
Модель считает, что это наблюдение равно 1 с вероятностью 0,93, и на самом деле этот пассажир выжил. Почему? Давайте воспользуемся объяснителем:
explainer = lime_tabular.LimeTabularExplainer(training_data=X_train, feature_names=X_names, class_names=np.unique(y_train), mode="classification")
explained = explainer.explain_instance(X_test[4], model.predict_proba, num_features=10)
explained.as_pyplot_figure()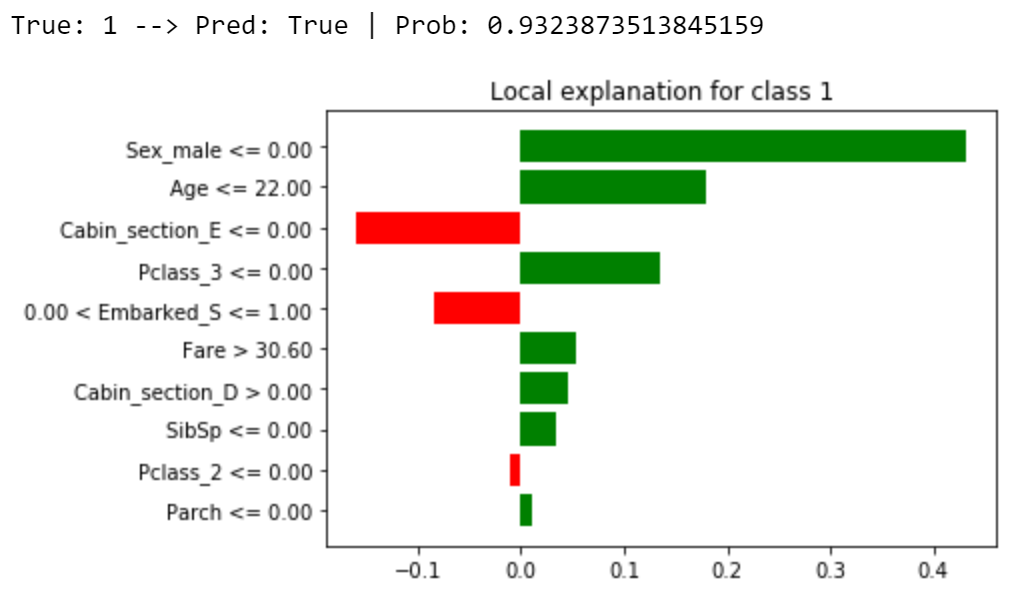
Основными факторами для этого конкретного прогноза являются то, что пассажир является женщиной (Sex_male = 0), молодой (возраст ≤ 22 лет) и путешествует 1-м классом (Pclass_3 = 0 и Pclass_2 = 0).
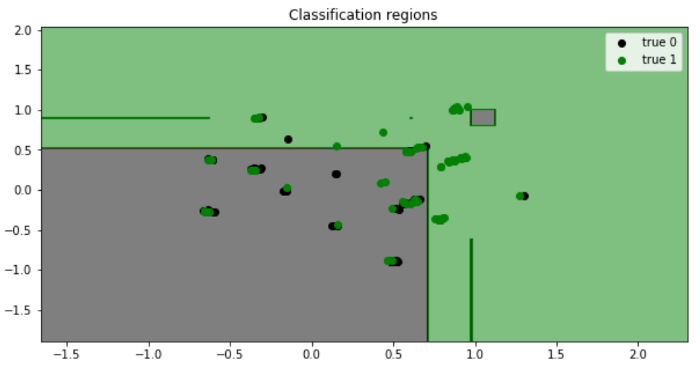
Матрица путаницы-отличный инструмент, чтобы показать, как прошло тестирование, но я также строю график регионы классификации чтобы дать наглядное представление о том, какие наблюдения модель предсказала правильно и что она пропустила. Для построения данных в 2 измерениях требуется некоторое уменьшение размерности (процесс уменьшения количества объектов путем получения набора основных переменных). Я приведу пример, используя СПС алгоритм суммирования данных в 2 переменные, полученные с помощью линейных комбинаций признаков.
## PCA
pca = decomposition.PCA(n_components=2)
X_train_2d = pca.fit_transform(X_train)
X_test_2d = pca.transform(X_test)
## train 2d model
model_2d = ensemble.GradientBoostingClassifier()
model_2d.fit(X_train, y_train)
## plot classification regions
from matplotlib.colors import ListedColormap
colors = {np.unique(y_test)[0]:"black", np.unique(y_test)[1]:"green"}
X1, X2 = np.meshgrid(np.arange(start=X_test[:,0].min()-1, stop=X_test[:,0].max()+1, step=0.01),
np.arange(start=X_test[:,1].min()-1, stop=X_test[:,1].max()+1, step=0.01))
fig, ax = plt.subplots()
Y = model_2d.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape)
ax.contourf(X1, X2, Y, alpha=0.5, cmap=ListedColormap(list(colors.values())))
ax.set(xlim=[X1.min(),X1.max()], ylim=[X2.min(),X2.max()], title="Classification regions")
for i in np.unique(y_test):
ax.scatter(X_test[y_test==i, 0], X_test[y_test==i, 1],
c=colors[i], label="true "+str(i))
plt.legend()
plt.show()Вывод
Эта статья была учебным пособием, демонстрирующим, как подойти к варианту использования классификации с помощью науки о данных. Я использовал набор данных Titanic в качестве примера, пройдя каждый шаг от анализа данных до модели машинного обучения.
В разделе «Исследование» я проанализировал случай одной категориальной переменной, одной числовой переменной и то, как они взаимодействуют друг с другом. Я привел пример разработки функций, извлекающих функции из необработанных данных. Что касается предварительной обработки, я объяснил, как обрабатывать отсутствующие значения и категориальные данные. Я показал различные способы выбора правильных функций, как использовать их для построения классификатора машинного обучения и как оценить производительность. В заключительном разделе я дал несколько советов о том, как улучшить объяснимость вашей модели машинного обучения.
Важно отметить, что я не описал, что произойдет после того, как ваша модель будет одобрена для развертывания. Просто имейте в виду, что вам нужно построить конвейер для автоматической обработки новых данных, которые вы будете периодически получать.
Теперь, когда вы знаете, как подойти к варианту использования науки о данных, вы можете применить этот код и метод к любой проблеме двоичной классификации, провести собственный анализ, построить собственную модель и даже объяснить ее.
Надеюсь, вам понравилось! Не стесняйтесь обращаться ко мне за вопросами и отзывами или просто поделиться своими интересными проектами.


