
Читая книгу по науке о данных или проходя курс, может показаться, что у вас есть отдельные фрагменты, но вы не совсем знаете, как их собрать. Сделать следующий шаг и решить полную проблему машинного обучения может быть непросто, но сохранение и завершение первого проекта придаст вам уверенности в решении любой проблемы, связанной с изучением данных. В этой серии статей будет рассмотрено полное решение для машинного обучения с набором данных из реального мира, чтобы вы могли увидеть, как все части собираются вместе.
Мы будем следовать общему рабочему процессу машинного обучения шаг за шагом:
- Очистка и форматирование данных
- Исследовательский анализ данных
- Разработка и выбор функций
- Сравните несколько моделей машинного обучения по показателям производительности
- Выполните настройку гиперпараметров на лучшей модели
- Оцените лучшую модель на тестовом наборе
- Интерпретируйте результаты модели
- Делайте выводы и документируйте работу
По пути мы увидим, как каждый шаг переходит в следующий и как конкретно реализовать каждую часть в Python. Полный проект доступен на GitHub, с первым блокнотом здесь.
(Как примечание, эта проблема изначально была дана мне как “задание” для экрана задания при запуске. После завершения работы мне предложили эту работу, но затем технический директор компании уволился, и они не смогли привлечь новых сотрудников. Я думаю, именно так все и происходит на стартовой сцене!)
Определение проблемы
Первый шаг, прежде чем мы приступим к кодированию, — это понять проблему, которую мы пытаемся решить, и доступные данные. В этом проекте мы будем работать с общедоступными данными об энергии зданий из Нью-Йорка.
Цель состоит в том, чтобы использовать данные об энергии для построения модели, которая может предсказать оценку энергетической звезды здания и интерпретировать результаты, чтобы найти факторы, влияющие на оценку.
Данные включают оценку Energy Star, что делает эту задачу контролируемым регрессионным машинным обучением:
- Под наблюдением: у нас есть доступ как к функциям, так и к цели, и наша цель состоит в том, чтобы обучить модель, которая может изучить сопоставление между ними
- Регрессия: Оценка Energy Star является непрерывной переменной
Мы хотим разработать модель, которая была бы одновременно точной — она могла бы предсказать оценку Energy Star, близкую к истинному значению, — и интерпретируемой — мы можем понять предсказания модели. Как только мы узнаем цель, мы сможем использовать ее для принятия решений при изучении данных и построении моделей.
Очистка Данных
Вопреки тому, во что вас заставляют верить большинство курсов по науке о данных, не каждый набор данных представляет собой идеально подобранную группу наблюдений без пропущенных значений или аномалий (если посмотреть на ваши наборы данных mtcars и iris). Реальные данные являются беспорядочными, что означает, что нам нужно очистить и привести их в приемлемый формат, прежде чем мы сможем даже начать анализ. Очистка данных-не гламурная, но необходимая часть большинства актуальных проблем науки о данных.
Во-первых, мы можем загрузить данные в виде Панд DataFrame и посмотреть:
import pandas as pd
import numpy as np
# Read in data into a dataframe
data = pd.read_csv('data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv')
# Display top of dataframe
data.head()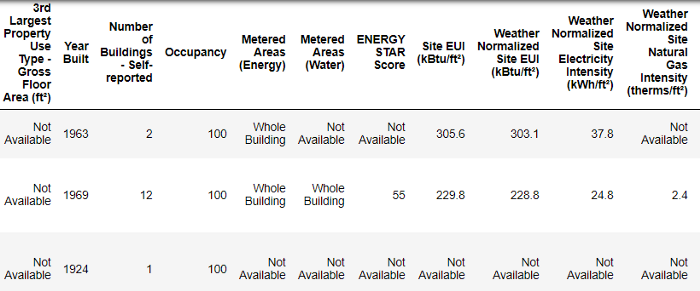
Это подмножество полных данных, которое содержит 60 столбцов. Уже сейчас мы видим пару проблем: во-первых, мы знаем, что хотим предсказать ENERGY STAR Score но мы не знаем, что означает любая из этих колонок. Хотя это не обязательно проблема — мы часто можем создать точную модель без каких — либо знаний о переменных, — мы хотим сосредоточиться на интерпретируемости, и может быть важно понять хотя бы некоторые столбцы.
Когда я изначально получил задание с самого начала, я не хотел спрашивать, что означают все имена столбцов, поэтому я посмотрел на имя файла,
и решил поискать “Местный закон 84”. Это привело меня на эту страницу, где объясняется, что это закон Нью-Йорка, требующий, чтобы все здания определенного размера сообщали об использовании энергии. Дальнейшие поиски привели меня ко всем определениям столбцов. Возможно, просмотр имени файла-очевидное место для начала, но для меня это было напоминанием о том, что нужно действовать медленно, чтобы не пропустить ничего важного!
Нам не нужно изучать все столбцы, но мы должны, по крайней мере, понять оценку Energy Star, которая описывается как:
Рейтинг от 1 до 100 процентов, основанный на самостоятельном использовании энергии за отчетный год. Оценка Energy Star — это относительная мера, используемая для сравнения энергоэффективности зданий.
Это устраняет первую проблему, но вторая проблема заключается в том, что отсутствующие значения кодируются как “Недоступные”. Это строка в Python, которая означает, что даже столбцы с числами будут храниться как object типы данных, потому что Pandas преобразует столбец с любыми строками в столбец всех строк. Мы можем видеть типы данных столбцов с помощью dataframe.info() метода:
# See the column data types and non-missing values
data.info()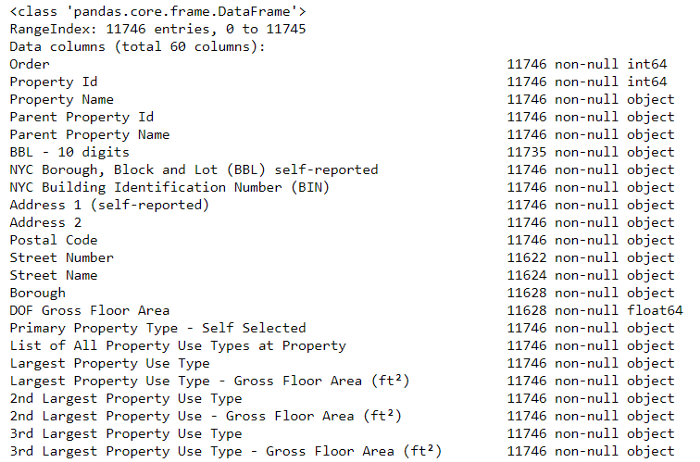
Конечно, некоторые столбцы, которые явно содержат числа (например, ft2), хранятся как объекты. Мы не можем выполнить численный анализ строк, поэтому их придется преобразовать в число (в частности float) типы данных!
Вот небольшой код на Python, который заменяет все “Недоступные” записи на не число (np.nan), которое можно интерпретировать как числа, а затем преобразует соответствующие столбцы в float тип данных:
# Replace all occurrences of Not Available with numpy not a number
data = data.replace({'Not Available': np.nan})
# Iterate through the columns
for col in list(data.columns):
# Select columns that should be numeric
if ('ft²' in col or 'kBtu' in col or 'Metric Tons CO2e' in col or 'kWh' in
col or 'therms' in col or 'gal' in col or 'Score' in col):
# Convert the data type to float
data[col] = data[col].astype(float)Как только правильные столбцы станут числами, мы сможем начать исследовать данные.
Отсутствующие данные и выбросы
В дополнение к неправильным типам данных, еще одной распространенной проблемой при работе с реальными данными является отсутствие значений. Они могут возникнуть по многим причинам и должны быть либо заполнены, либо удалены до того, как мы обучим модель машинного обучения. Во-первых, давайте поймем, сколько пропущенных значений содержится в каждом столбце (код см. в записной книжке).
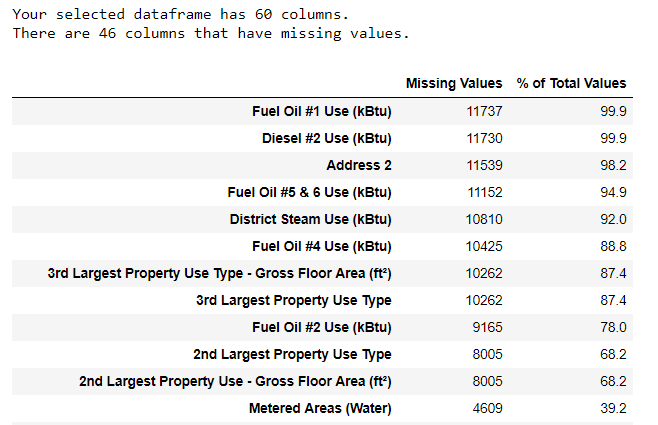
(Для создания этой таблицы я использовал функцию с этого форума переполнения стека).
Хотя мы всегда хотим быть осторожными при удалении информации, если в столбце высокий процент пропущенных значений, то это, вероятно, не будет полезно для нашей модели. Пороговое значение для удаления столбцов должно зависеть от проблемы (здесь обсуждается), и для этого проекта мы удалим любые столбцы с более чем 50% отсутствующих значений.
На этом этапе мы также можем захотеть удалить выбросы. Это может быть связано с опечатками при вводе данных, ошибками в единицах измерения, или это могут быть законные, но экстремальные значения. Для этого проекта мы удалим аномалии на основе определения экстремальных выбросов:
- Ниже первого квартиля − 3 * межквартильный диапазон
- Выше третьего квартиля + 3 * межквартильный диапазон
(Код для удаления столбцов и аномалий см. в записной книжке). В конце процесса очистки данных и удаления аномалий у нас остается более 11 000 зданий и 49 объектов.
Исследовательский Анализ Данных
Теперь, когда утомительный, но необходимый этап очистки данных завершен, мы можем перейти к изучению наших данных! Исследовательский анализ данных (EDA) — это открытый процесс, в ходе которого мы вычисляем статистику и составляем цифры, чтобы найти тенденции, аномалии, закономерности или взаимосвязи в данных.
Короче говоря, цель EDA-узнать, что могут рассказать нам наши данные. Как правило, он начинается с обзора высокого уровня, затем сужается до конкретных областей, поскольку мы находим интересные части данных. Результаты могут быть интересны сами по себе, или они могут быть использованы для информирования о наших решениях в области моделирования, например, помогая нам решить, какие функции использовать.
Графики с Одной Переменной
Цель состоит в том, чтобы предсказать оценку Energy Star (переименованную score в наших данных), поэтому разумным местом для начала является изучение распределения этой переменной. Гистограмма-это простой, но эффективный способ визуализации распределения одной переменной, и ее легко использовать matplotlib.
import matplotlib.pyplot as plt
# Histogram of the Energy Star Score
plt.style.use('fivethirtyeight')
plt.hist(data['score'].dropna(), bins = 100, edgecolor = 'k');
plt.xlabel('Score'); plt.ylabel('Number of Buildings');
plt.title('Energy Star Score Distribution');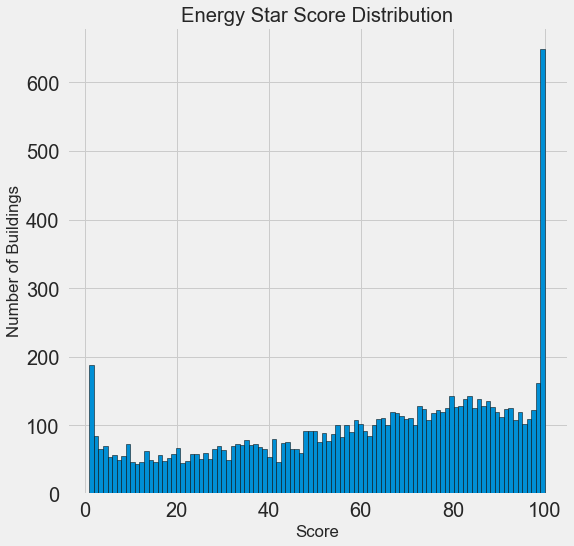
Это выглядит довольно подозрительно! Оценка Energy Star является процентильным рангом, что означает, что мы ожидаем равномерного распределения, при этом каждый балл присваивается одному и тому же количеству зданий. Однако непропорционально большое количество зданий имеют либо самый высокий, 100, либо самый низкий, 1 балл (чем выше, тем лучше для оценки Energy Star).
Если мы вернемся к определению оценки, мы увидим, что она основана на “самоотчете об использовании энергии”, что может объяснить очень высокие баллы. Просить владельцев зданий сообщать о своем собственном потреблении энергии-все равно что просить студентов сообщать о своих собственных результатах на тесте! В результате это, вероятно, не самый объективный показатель энергоэффективности здания.
Если бы у нас было неограниченное количество времени, мы могли бы захотеть выяснить, почему так много зданий имеют очень высокие и очень низкие баллы, которые мы могли бы получить, выбрав эти здания и посмотрев, что у них общего. Однако наша цель состоит только в том, чтобы предсказать счет, а не в том, чтобы разработать лучший метод подсчета очков зданий! Мы можем отметить в нашем отчете, что результаты имеют подозрительное распределение, но наше основное внимание уделяется прогнозированию результатов.
В поисках отношений
Основная часть EDA заключается в поиске взаимосвязей между функциями и целью. Переменные, коррелирующие с целью, полезны для модели, поскольку их можно использовать для прогнозирования цели. Один из способов изучить влияние категориальной переменной (которая принимает только ограниченный набор значений) на цель-это построить график плотности с использованием seaborn библиотеки.
График плотности можно рассматривать как сглаженную гистограмму, поскольку он показывает распределение одной переменной. Мы можем раскрасить график плотности по классам, чтобы увидеть, как категориальная переменная изменяет распределение. Следующий код создает график плотности оценки Энергетической звезды, окрашенный типом здания (ограничено типами зданий с более чем 100 точками данных).:
# Create a list of buildings with more than 100 measurements
types = data.dropna(subset=['score'])
types = types['Largest Property Use Type'].value_counts()
types = list(types[types.values > 100].index)
# Plot of distribution of scores for building categories
figsize(12, 10)
# Plot each building
for b_type in types:
# Select the building type
subset = data[data['Largest Property Use Type'] == b_type]
# Density plot of Energy Star scores
sns.kdeplot(subset['score'].dropna(),
label = b_type, shade = False, alpha = 0.8);
# label the plot
plt.xlabel('Energy Star Score', size = 20); plt.ylabel('Density', size = 20);
plt.title('Density Plot of Energy Star Scores by Building Type', size = 28);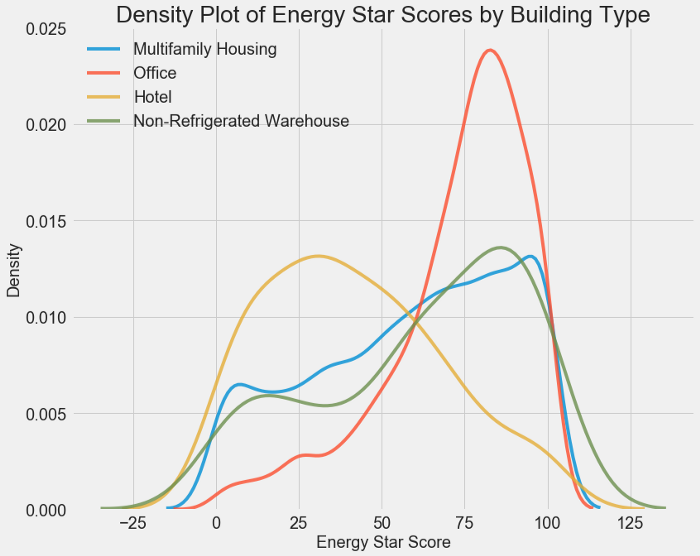
Мы видим, что тип здания оказывает значительное влияние на оценку Energy Star. Офисные здания, как правило, имеют более высокий балл, в то время как отели имеют более низкий балл. Это говорит нам о том, что мы должны включить тип здания в наше моделирование, потому что это действительно влияет на цель. В качестве категориальной переменной нам придется однократно кодировать тип здания.
Аналогичный график можно использовать для отображения оценки Energy Star по районам:
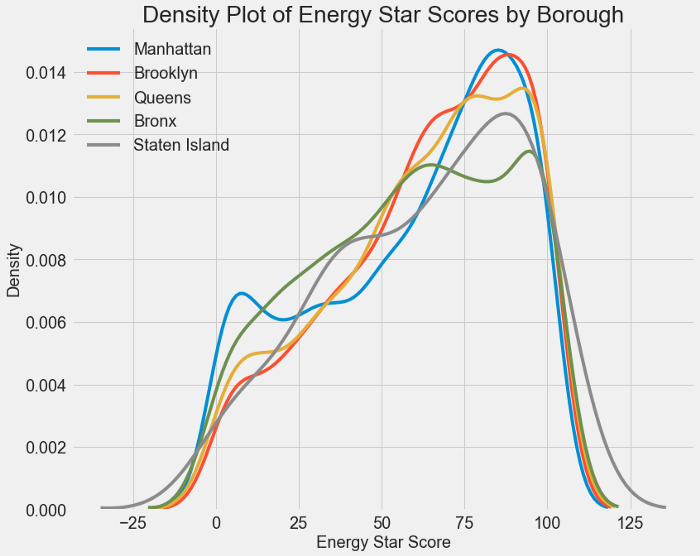
Район, похоже, не оказывает такого большого влияния на оценку, как тип здания. Тем не менее, мы, возможно, захотим включить его в нашу модель, потому что между районами есть небольшие различия.
Для количественной оценки взаимосвязей между переменными мы можем использовать коэффициент корреляции Пирсона. Это мера силы и направления линейной зависимости между двумя переменными. Оценка +1 является совершенно линейной положительной зависимостью, а оценка -1 является совершенно отрицательной линейной зависимостью. Несколько значений коэффициента корреляции показаны ниже:
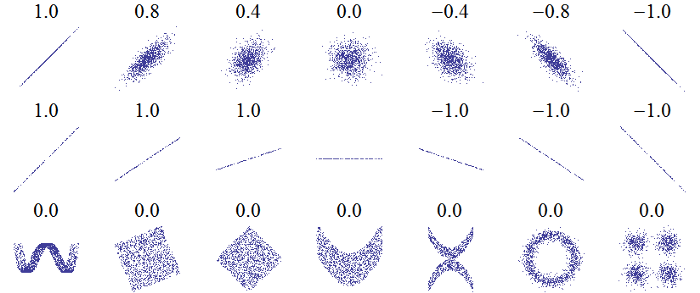
Хотя коэффициент корреляции не может отражать нелинейные взаимосвязи, это хороший способ начать выяснять, как связаны переменные. В Pandas мы можем легко вычислить корреляции между любыми столбцами в фрейме данных:
# Find all correlations with the score and sort
correlations_data = data.corr()['score'].sort_values()Наиболее отрицательные (слева) и положительные (справа) корреляции с целью:

Существует несколько сильных отрицательных корреляций между функциями и целью, причем наиболее отрицательными являются различные категории EUI (эти показатели немного различаются в том, как они рассчитываются). EUI — Интенсивность энергопотребления — это количество энергии, потребляемой зданием, деленное на площадь зданий.
Графики с двумя Переменными
Чтобы визуализировать взаимосвязи между двумя непрерывными переменными, мы используем диаграммы рассеяния.
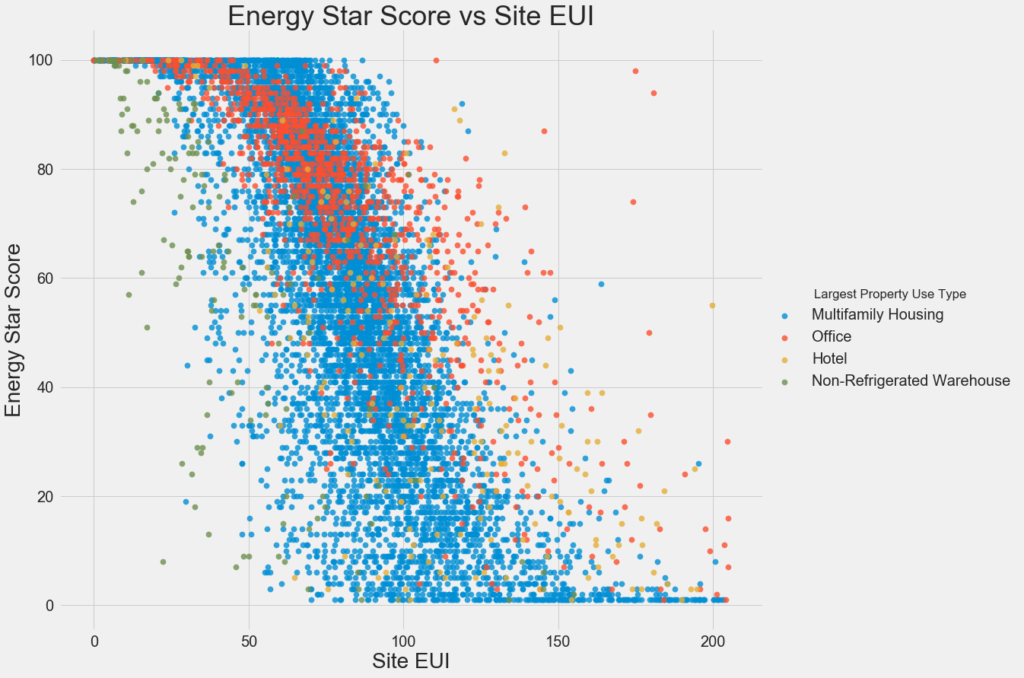
Этот график позволяет нам визуализировать, как выглядит коэффициент корреляции -0,7. По мере уменьшения EUI сайта оценка Energy Star увеличивается, и эта взаимосвязь остается неизменной для всех типов зданий.
Окончательный исследовательский сюжет, который мы сделаем, известен как Парный сюжет. Это отличный инструмент для исследования, потому что он позволяет нам видеть взаимосвязи между несколькими парами переменных, а также распределения отдельных переменных. Здесь мы используем библиотеку визуализации seaborn и PairGrid функцию для создания графика пар с диаграммами рассеяния на верхнем треугольнике, гистограммами по диагонали и 2D-графиками плотности ядра и коэффициентами корреляции на нижнем треугольнике.
# Extract the columns to plot
plot_data = features[['score', 'Site EUI (kBtu/ft²)',
'Weather Normalized Source EUI (kBtu/ft²)',
'log_Total GHG Emissions (Metric Tons CO2e)']]
# Replace the inf with nan
plot_data = plot_data.replace({np.inf: np.nan, -np.inf: np.nan})
# Rename columns
plot_data = plot_data.rename(columns = {'Site EUI (kBtu/ft²)': 'Site EUI',
'Weather Normalized Source EUI (kBtu/ft²)': 'Weather Norm EUI',
'log_Total GHG Emissions (Metric Tons CO2e)': 'log GHG Emissions'})
# Drop na values
plot_data = plot_data.dropna()
# Function to calculate correlation coefficient between two columns
def corr_func(x, y, **kwargs):
r = np.corrcoef(x, y)[0][1]
ax = plt.gca()
ax.annotate("r = {:.2f}".format(r),
xy=(.2, .8), xycoords=ax.transAxes,
size = 20)
# Create the pairgrid object
grid = sns.PairGrid(data = plot_data, size = 3)
# Upper is a scatter plot
grid.map_upper(plt.scatter, color = 'red', alpha = 0.6)
# Diagonal is a histogram
grid.map_diag(plt.hist, color = 'red', edgecolor = 'black')
# Bottom is correlation and density plot
grid.map_lower(corr_func);
grid.map_lower(sns.kdeplot, cmap = plt.cm.Reds)
# Title for entire plot
plt.suptitle('Pairs Plot of Energy Data', size = 36, y = 1.02);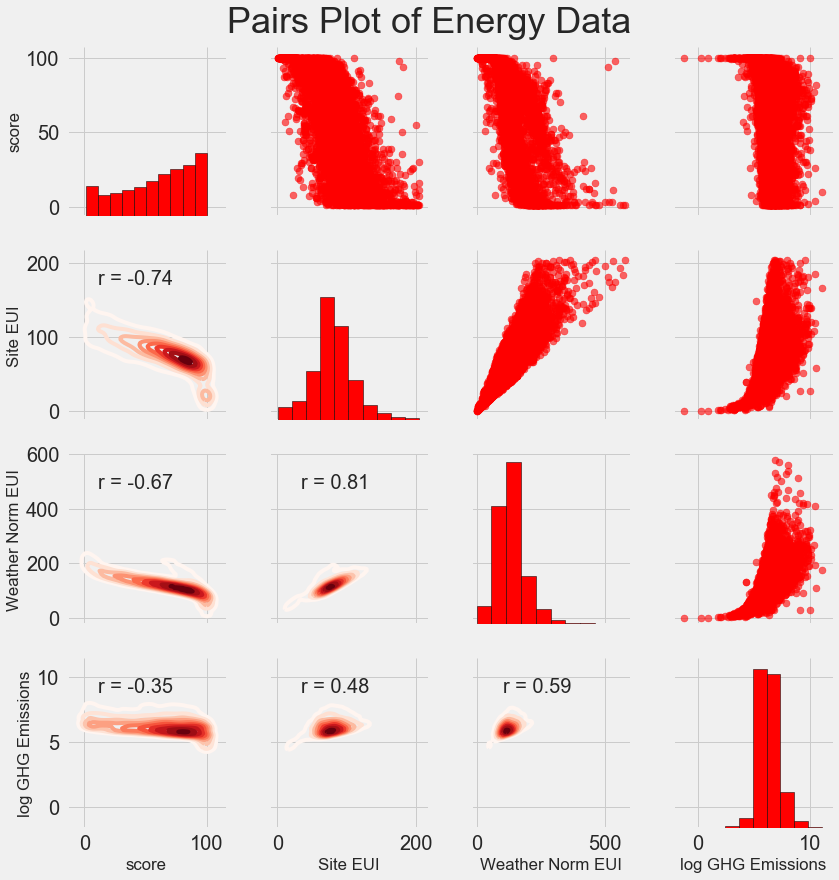
Чтобы увидеть взаимодействие между переменными, мы ищем, где строка пересекается со столбцом. Например, чтобы увидеть корреляцию Weather Norm EUIс score, мы смотрим в Weather Norm EUIстроку и scoreстолбец и видим коэффициент корреляции -0,67. В дополнение к тому, что такие графики выглядят круто, они могут помочь нам решить, какие переменные включать в моделирование.
Разработка и выбор функций
Разработка и выбор функций часто обеспечивают наибольшую отдачу от времени, затраченного на решение проблемы машинного обучения. Прежде всего, давайте определимся, в чем заключаются эти две задачи:
- Разработка функций: Процесс сбора необработанных данных и извлечения или создания новых функций. Это может означать преобразование переменных, таких как натуральный логарифм и квадратный корень, или однократное кодирование категориальных переменных, чтобы их можно было использовать в модели. Как правило, я рассматриваю разработку функций как создание дополнительных функций из необработанных данных.
- Выбор функций: Процесс выбора наиболее релевантных функций в данных. При выборе функций мы удаляем функции, чтобы помочь модели лучше обобщать новые данные и создавать более интерпретируемую модель. Как правило, я рассматриваю выбор функций как вычитание функций, поэтому у нас остаются только те, которые являются наиболее важными.
Модель машинного обучения может учиться только на данных, которые мы ей предоставляем, поэтому обеспечение того, чтобы данные включали всю необходимую информацию для нашей задачи, имеет решающее значение. Если мы не передаем модели правильные данные, то мы настраиваем ее на сбой, и нам не следует ожидать, что она научится!
Для этого проекта мы предпримем следующие шаги по разработке функций:
- Однократное кодирование категориальных переменных (район и тип использования недвижимости)
- Добавьте преобразование в натуральном логарифме числовых переменных
Однократное кодирование необходимо для включения категориальных переменных в модель. Алгоритм машинного обучения не может понять тип здания “офис”, поэтому мы должны записать его как 1, если здание является офисом, и 0 в противном случае.
Добавление преобразованных функций может помочь нашей модели изучить нелинейные взаимосвязи в данных. Использование квадратного корня, натурального логарифма или различных степеней функций является обычной практикой в науке о данных и может основываться на знаниях предметной области или на том, что лучше всего работает на практике. Здесь мы включим естественный лог всех числовых признаков.
Следующий код выбирает числовые объекты, выполняет логарифмические преобразования этих объектов, выбирает два категориальных объекта, одним нажатием кодирует эти объекты и объединяет два набора вместе. Это кажется большой работой, но в Pandas это относительно просто!
# Copy the original data
features = data.copy()
# Select the numeric columns
numeric_subset = data.select_dtypes('number')
# Create columns with log of numeric columns
for col in numeric_subset.columns:
# Skip the Energy Star Score column
if col == 'score':
next
else:
numeric_subset['log_' + col] = np.log(numeric_subset[col])
# Select the categorical columns
categorical_subset = data[['Borough', 'Largest Property Use Type']]
# One hot encode
categorical_subset = pd.get_dummies(categorical_subset)
# Join the two dataframes using concat
# Make sure to use axis = 1 to perform a column bind
features = pd.concat([numeric_subset, categorical_subset], axis = 1)После этого процесса у нас есть более 11 000 наблюдений (зданий) со 110 столбцами (объектами). Не все из этих функций, вероятно, будут полезны для прогнозирования оценки Energy Star, поэтому теперь мы перейдем к выбору функций, чтобы удалить некоторые переменные.
Выбор функций
Многие из 110 функций, которые мы имеем в наших данных, являются избыточными, потому что они сильно коррелируют друг с другом. Например, вот график EUI сайта по сравнению с нормализованным по погоде EUI сайта, коэффициент корреляции которого составляет 0,997.
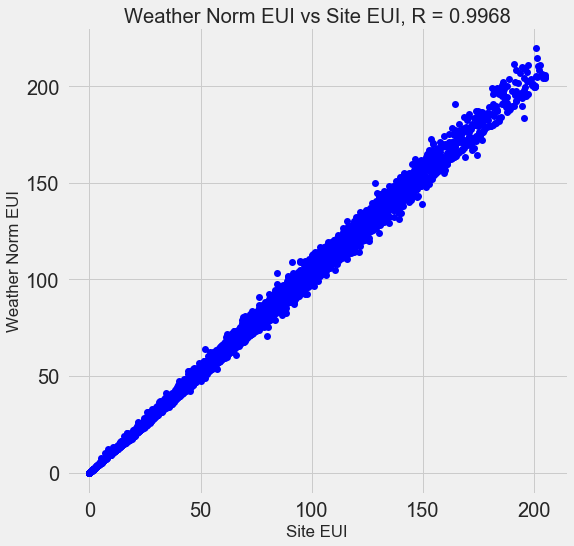
Функции, которые сильно коррелируют друг с другом, называются коллинеарными, и удаление одной из переменных в этих парах функций часто может помочь модели машинного обучения обобщить и сделать ее более интерпретируемой. (Я должен отметить, что мы говорим о корреляции функций с другими функциями, а не о корреляции с целью, которая помогает нашей модели!)
Существует ряд методов расчета коллинеарности между объектами, одним из наиболее распространенных из которых является коэффициент инфляции дисперсии. В этом проекте мы будем использовать коэффициент корреляции для идентификации и удаления коллинеарных объектов. Мы отбросим одну из пары функций, если коэффициент корреляции между ними больше 0,6.
Хотя это значение может показаться произвольным, я попробовал несколько различных пороговых значений, и этот выбор дал лучшую модель. Машинное обучение-это эмпирическая область, и часто оно связано с экспериментами и поиском того, что работает лучше всего! После выбора функций у нас остается всего 64 функции и 1 цель.
# Split into 70% training and 30% testing set
X, X_test, y, y_test = train_test_split(features, targets,
test_size = 0.3,
random_state = 42)Теперь мы можем рассчитать наивную базовую производительность:
# Function to calculate mean absolute error
def mae(y_true, y_pred):
return np.mean(abs(y_true - y_pred))
baseline_guess = np.median(y)
print('The baseline guess is a score of %0.2f' % baseline_guess)
print("Baseline Performance on the test set: MAE = %0.4f" % mae(y_test, baseline_guess))Исходное предположение-оценка 66,00
Базовая производительность в тестовом наборе: MAE = 24,5164
Наивная оценка отклоняется примерно на 25 баллов в тестовом наборе. Оценка колеблется в пределах 1-100, так что это представляет собой ошибку в 25%, довольно низкую планку, которую можно превзойти!
Выводы
В этой статье мы рассмотрели первые три шага проблемы машинного обучения. Определившись с вопросом, мы:
- Очистил и отформатировал необработанные данные
- Выполнил исследовательский анализ данных, чтобы узнать о наборе данных
- Разработан набор функций, которые мы будем использовать для наших моделей
Наконец, мы также завершили решающий этап создания базовой линии, по которой мы можем судить о наших алгоритмах машинного обучения.

