#python #pandas #counter
Вопрос:
Я пытаюсь визуализировать корреляцию между значениями POS. Из приведенного ниже списка я хочу сгенерировать фрейм данных, в котором столбцы равны keys , а первая строка равна values .
Мне это нужно, чтобы, после, построить df.corr()
Вот переменные:
keys = Counter(list_tag).keys() keys dict_keys(['NNP', 'VBZ', 'DT', 'NN', '.', 'PRP', 'VBD', 'IN', 'JJ', 'NNS', ',', '``', 'NNPS', "''", 'PRP
values = Counter(list_tag).values() values
dict_values dict_values([282, 110, 259, 426, 106, 132, 60, 275, 204, 98, 119, 12, 3, 11, 41, 24, 80, 46, 25, 177, 7, 14, 30, 64, 112, 13, 10, 10, 21, 45, 42, 11, 12, 8, 12, 1, 1, 1, 2, 4])
Моя беда в том, что: зовущий df = pd.DataFrame(Counter(list_tag), index=Counter(list_tag).keys()) Как показано ниже, я пишу что-то неправильно, потому что мне нужна только первая строка.
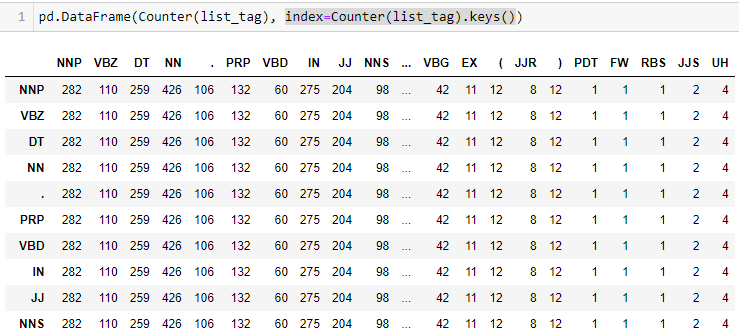
Есть ли эффективное решение для достижения этой цели без ручного отбрасывания df.iloc[2:] благодарности!
Комментарии:
1. Я думаю, что вам не хватает a .ценностей. Это должно быть похоже
pd.DataFrame(Counter(list_tag).values(), index=Counter(list_tag).keys()). Также вы можете сохранитьCounter(list_tag)в переменной
Ответ №1:
keys = ['NNP', 'VBZ', 'DT', 'NN', '.', 'PRP', 'VBD', 'IN', 'JJ', 'NNS', ',', '``', 'NNPS', "''", 'PRP
, 'CD', 'VB', 'TO', 'POS', 'RB', 'RBR', 'WP', 'MD', 'VBP', 'CC', 'WRB', 'WDT', 'RP', ':', 'VBN', 'VBG', 'EX', '(', 'JJR', ')', 'PDT', 'FW', 'RBS', 'JJS', 'UH'])
Моя беда в том, что: зовущий df = pd.DataFrame(Counter(list_tag), index=Counter(list_tag).keys()) Как показано ниже, я пишу что-то неправильно, потому что мне нужна только первая строка.
Есть ли эффективное решение для достижения этой цели без ручного отбрасывания df.iloc[2:] благодарности!
Комментарии:
1. Я думаю, что вам не хватает a .ценностей. Это должно быть похоже
pd.DataFrame(Counter(list_tag).values(), index=Counter(list_tag).keys()). Также вы можете сохранитьCounter(list_tag)в переменной
Ответ №1:
, 'CD', 'VB', 'TO', 'POS', 'RB', 'RBR', 'WP', 'MD', 'VBP', 'CC', 'WRB', 'WDT', 'RP', ':', 'VBN', 'VBG', 'EX', '(', 'JJR', ')', 'PDT', 'FW', 'RBS', 'JJS', 'UH'] values = [282, 110, 259, 426, 106, 132, 60, 275, 204, 98, 119, 12, 3, 11, 41, 24, 80, 46, 25, 177, 7, 14, 30, 64, 112, 13, 10, 10, 21, 45, 42, 11, 12, 8, 12, 1, 1, 1, 2, 4] df = pd.DataFrame(values, index=keys).transpose()
, ‘CD’, ‘VB’, ‘TO’, ‘POS’, ‘RB’, ‘RBR’, ‘WP’, ‘MD’, ‘VBP’, ‘CC’, ‘WRB’, ‘WDT’, ‘RP’, ‘:’, ‘VBN’, ‘VBG’, ‘EX’, ‘(‘, ‘JJR’, ‘)’, ‘PDT’, ‘FW’, ‘RBS’, ‘JJS’, ‘UH’])
Моя беда в том, что: зовущий df = pd.DataFrame(Counter(list_tag), index=Counter(list_tag).keys()) Как показано ниже, я пишу что-то неправильно, потому что мне нужна только первая строка.
Есть ли эффективное решение для достижения этой цели без ручного отбрасывания df.iloc[2:] благодарности!
Комментарии:
1. Я думаю, что вам не хватает a .ценностей. Это должно быть похоже
pd.DataFrame(Counter(list_tag).values(), index=Counter(list_tag).keys()). Также вы можете сохранитьCounter(list_tag)в переменной