#python #regex
#c# #.net #sql-сервер #регулярное выражение #sql-server-2012
Вопрос:
В T-SQL я сгенерировал уникальный идентификатор с помощью функции NEWID(). Например:
723952A7-96C6-421F-961F-80E66A4F29D2
Затем все тире ( - ) удаляются, и это выглядит следующим образом:
723952A796C6421F961F80E66A4F29D2
Теперь мне нужно преобразовать приведенную выше строку в допустимую, UNIQUEIDENTIFIER используя следующий формат xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx и снова установив тире.
Для достижения этой цели я использую SQL CLR реализацию C# RegexMatches функции с этим ^.{8}|.{12}$|.{4} регулярным выражением, которое дает мне это:
SELECT *
FROM [dbo].[RegexMatches] ('723952A796C6421F961F80E66A4F29D2', '^.{8}|.{12}$|.{4}')

Используя вышесказанное, я могу легко создать правильное, UNIQUEIDENTIFIER но мне интересно, как OR оператор вычисляется в регулярном выражении. Например, следующее не будет работать:
SELECT *
FROM [dbo].[RegexMatches] ('723952A796C6421F961F80E66A4F29D2', '^.{8}|.{4}|.{12}$')

Уверен ли он, что первое регулярное выражение сначала будет соответствовать началу и концу строки, затем другим значениям и всегда возвращает совпадения в этом порядке (у меня будут проблемы, если, например, 96C6 будет сопоставлено после 421F ).
Комментарии:
1. Кроме того, причина, по которой
^.{8}|.{4}|.{12}$возвращаются блоки по четыре вместо последнего из 12, связана с тем фактом, что используется первоеor (|)значение, которое совпадает, не самое точное. Анализатор регулярных выражений видит.{4}прежде, чем он увидит.{12}$, и поэтому сопоставляет их в квадратах.2. @EBrown, эта ситуация является частью сложного приложения. Я не могу изменить способ, которым это делается. Просто нужно найти способ справиться с этой ситуацией.
3. @EBrown, значит, он всегда соответствует
ORблоку в порядке?4. Почему вы используете регулярное выражение, чтобы разделить это? Вы точно знаете, где тире должны быть вставлены повторно. Например.
STUFF(STUFF(STUFF(STUFF(UnDashedValue,21,0,'-'),17,0,'-'),13,0,'-'),9,0,'-')выполняет работу.5. Мы должны работать с разными определениями clear . Т. е. тот факт, что вам приходится задавать вопрос о варианте регулярного выражения, мне кажется, что это может быть не «ясно».
Ответ №1:
Если вас интересует, что происходит при использовании | оператора чередования, ответ прост: механизм регулярных выражений обрабатывает выражение и входную строку слева на справа.
Взяв в качестве примера шаблон, который у вас есть, ^.{8}|.{12}$|.{4} начинает проверку входной строки слева и проверяет наличие ^.{8} первых 8 символов. Находит их, и это совпадение. Затем идет дальше и находит последние 12 символов с .{12}$ , и снова есть совпадение. Затем сопоставляются любые 4-символьные строки.
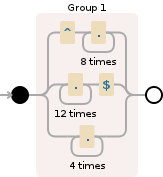
Далее у вас есть ^.{8}|.{4}|.{12}$ . Выражение снова анализируется слева направо, сначала сопоставляются первые 8 символов, но затем будут сопоставлены только последовательности из 4 символов, .{12} которые никогда не сработают, потому что будут .{4} совпадения!
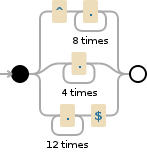
Ответ №2:
Ваше регулярное выражение ^.{8}|.{12}$|.{4} вычисляется как:
Начиная с любого символа, кроме n { Ровно 8 раз}
ИЛИ любой символ, кроме n { Ровно 12 раз}
ИЛИ любой символ, кроме n {Ровно 4 раза} глобально
Это означает, что все, что находится после 4 символов в строке, будет сопоставлено, потому что где-то в строке из > 4 символов есть 4 символа в строке.
1 [false]
12 [false]
123 [false]
1234 [верно]
12345 [верно]
123456 [верно]
1234567 [верно]
12345678 [верно]
123456789 [верно]
1234567890 [верно]
12345678901 [верно]
123456789012 [верно]
Возможно, вы ищете:
^.{8}$|^.{12}$|^.{4}$
Что дает вам:
1 [false]
12 [false]
123 [false]
1234 [верно]
12345 [false]
123456 [false]
1234567 [false]
12345678 [верно]
123456789 [false]
1234567890 [false]
12345678901 [false]
123456789012 [верно]