#deep-learning #lstm #recurrent-neural-network #stacked
#глубокое обучение #lstm #рекуррентная нейронная сеть #многоуровневый
Вопрос:
У меня возникают некоторые трудности с пониманием потока ввода-вывода слоев в многоуровневых сетях LSTM. Допустим, я создал многоуровневую сеть LSTM, подобную приведенной ниже:
# parameters
time_steps = 10
features = 2
input_shape = [time_steps, features]
batch_size = 32
# model
model = Sequential()
model.add(LSTM(64, input_shape=input_shape, return_sequences=True))
model.add(LSTM(32,input_shape=input_shape))
где наша многоуровневая сеть LSTM состоит из 2 уровней LSTM с 64 и 32 скрытыми блоками соответственно. В этом сценарии мы ожидаем, что на каждом временном шаге 1-й уровень LSTM — LSTM (64) — будет передавать в качестве входных данных 2-му уровню LSTM -LSTM(32) — вектор размера [batch_size, time-step, hidden_unit_length] , который будет представлять скрытое состояние 1-го уровня LSTM на текущем временном шаге. Что меня смущает, так это:
- Получает ли 2-й уровень LSTM -LSTM(32) as
X(t)(в качестве входных данных) скрытое состояние 1-го уровня -LSTM (64) — которое имеет размер[batch_size, time-step, hidden_unit_length]и передает его через свою собственную скрытую сеть — в данном случае состоящую из 32 узлов -? - Если первое верно, то почему
input_shapeзначения 1-го -LSTM (64) — и 2-го -LSTM (32) — одинаковы, когда 2-й обрабатывает только скрытое состояние 1-го уровня? Разве в нашем случае не должно бытьinput_shapeустановлено значение[32, 10, 64]быть?
Я нашел приведенную ниже визуализацию LSTM очень полезной (найдена здесь), но она не распространяется на многоуровневые сети lstm: 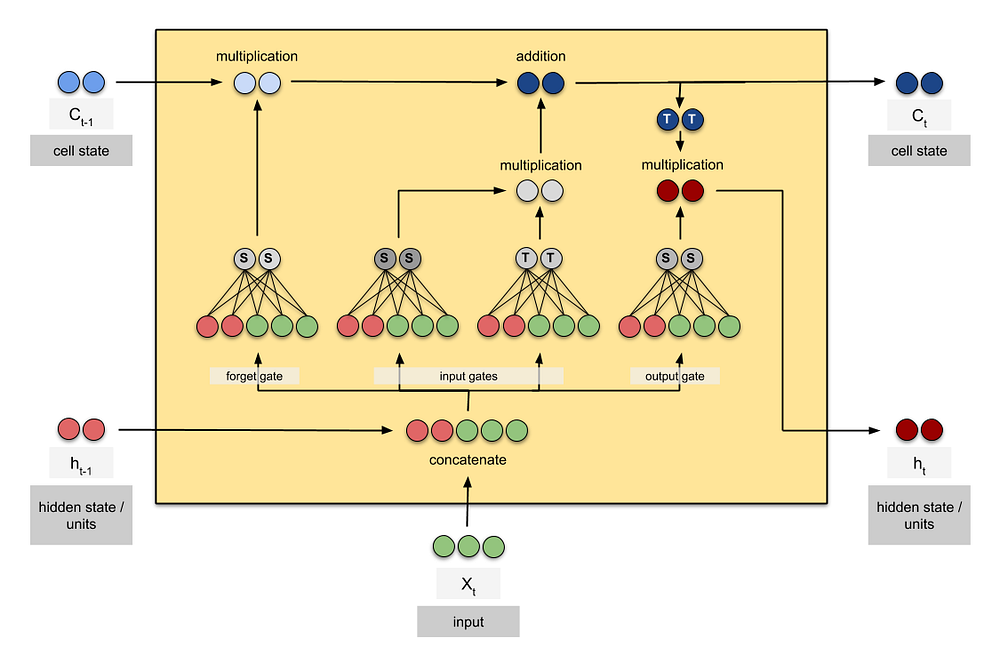
Любая помощь была бы высоко оценена. Спасибо!
Ответ №1:
input_shape Требуется только для первого уровня. Последующие уровни принимают выходные данные предыдущего уровня в качестве входных данных (поэтому их input_shape значение аргумента игнорируется)
Модель ниже
model = Sequential()
model.add(LSTM(64, return_sequences=True, input_shape=(5, 2)))
model.add(LSTM(32))
представьте нижеприведенную архитектуру

По которому вы можете это проверить model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_26 (LSTM) (None, 5, 64) 17152
_________________________________________________________________
lstm_27 (LSTM) (None, 32) 12416
=================================================================
Замена строки
model.add(LSTM(32))
с
model.add(LSTM(32, input_shape=(1000000, 200000)))
все равно предоставит вам ту же архитектуру (проверьте с помощью model.summary() ), потому что input_shape игнорируется, поскольку он принимает в качестве входных данных тензорный вывод предыдущего уровня.
И если вам нужна архитектура «последовательность в последовательность», как показано ниже

вы должны использовать код:
model = Sequential()
model.add(LSTM(64, return_sequences=True, input_shape=(5, 2)))
model.add(LSTM(32, return_sequences=True))
который должен возвращать модель
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_32 (LSTM) (None, 5, 64) 17152
_________________________________________________________________
lstm_33 (LSTM) (None, 5, 32) 12416
=================================================================
Комментарии:
1. это уже помогает, но как перейти от 64 к 32? Вы используете только последние 32 из 64 выходных данных? И как это происходит с глубоким двунаправленным LSTM? процесс понятен мне только в том случае, если у вас одинаковое количество модулей LSTM на каждом уровне…
2. @S.Maria LSTM имеет размер ввода и выходной / скрытый размер. Внутри он использует стробирующий механизм для преобразования входных данных в скрытые / выходные данные. Здесь мой размер входных данных равен 64, а размер выходных данных равен 32. В случае bi-LSTM вы получаете два выходных данных, по одному для каждого направления. Итак, если ваш размер выходных данных равен 32, вы получите 32 для left-> right LSTM и 32 для right-> left LSTM.
3. У меня вопрос, как осуществляется взаимосвязь между первым уровнем из 64 блоков и 32 блоками?
Ответ №2:
В документе keras упоминается, что входные данные являются [batch_size, time-step, input_dim] , а не [batch_size, time-step, hidden_unit_length] , поэтому я думаю, что 64, 32, соответствующие X-входным данным, имеют 64 функции, а LSTM-32 имеет 32 функции для каждого временного шага.