#regex
#регулярное выражение
Вопрос:
Я хочу сопоставить два типа URL-адресов:
(1) www.test.de/type1/12345/this-is-a-title.html
(2) www.test.de/category/another-title-oh-yes.html
В первом типе я хочу соответствовать «12345».
Во втором типе я хочу соответствовать «категория / другое-название-о-да».
Вот что я придумал:
(?:(?:.de/type1/([d]*)/)|.de/([S] ).html)
Это возвращает следующее:
Для типа (1):
Match group 1: 12345
Match group 2:
Для типа (2):
Match group:
Match group 2: category/another-title-oh-yes
Как вы можете видеть, оно уже работает довольно хорошо.
Однако по разным причинам мне нужно, чтобы регулярное выражение возвращало только одну группу совпадений. Есть ли способ добиться этого?
Комментарии:
1. вы можете объединить 2 совпадающие строки вместе, поскольку по крайней мере 1 всегда пуста в вашем регулярном выражении..
Ответ №1:
Java / PHP/Python
Получите обе совпадающие группы с индексом 1, используя как отрицательный прогноз, так и положительный взгляд назад.
((?<=.de/type1/)d |(?<=.de/)(?!type1)[^.] )
Существует два шаблона регулярных выражений, которые являются ORed.
Первый шаблон регулярного выражения ищет 12345
Второй шаблон регулярного выражения ищет category/another-title-oh-yes .
Примечание:
- Каждый шаблон регулярного выражения должен соответствовать ровно одному совпадению в каждом URL
-
Объедините весь шаблон регулярного выражения внутри круглой скобки
(...|...)и удалите круглые скобки из[^.]иd, где:[^.] find anything until dot is found d find one or more digits
Вот онлайн-демонстрация на regex101
Ввод:
www.test.de/type1/12345/this-is-a-title.html
www.test.de/category/another-title-oh-yes.html
Вывод:
MATCH 1
1. [18-23] `12345`
MATCH 2
1. [57-86] `category/another-title-oh-yes`
JavaScript
попробуйте это и получите обе совпадающие группы с индексом 2.
((?:.de/type1/)(d )|(?:.de/)(?!type1)([^.] ))
Вот онлайн-демонстрация на regex101.
Ввод:
www.test.de/type1/12345/this-is-a-title.html
www.test.de/category/another-title-oh-yes.html
Вывод:
MATCH 1
1. `.de/type1/12345`
2. `12345`
MATCH 2
1. `.de/category/another-title-oh-yes`
2. `category/another-title-oh-yes`
Комментарии:
1. Это работает удивительно хорошо, я даже не знал, что подобное возможно! Спасибо!
Ответ №2:
Возможно, это:
^www.test.de/(type1/(.*).|(.*).html)$
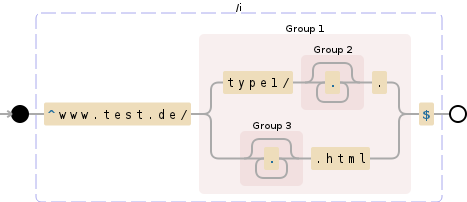
Тогда, например:
var str = "www.test.de/type1/12345/this-is-a-title.html"
var regex = /^www.test.de/(type1/(.*).|(.*).html)$/
console.log(str.match(regex))
Это выведет массив, первым элементом которого является строка, вторым — все, что стоит после адреса веб-сайта, третьим — то, что соответствует типу 1, а четвертым элементом является остальное.
Вы можете сделать что-то вроде var matches = str.match(regex); return matches[2] || matches[3];
Комментарии:
1. Спасибо за ваш ответ, но это возвращает три группы совпадений, тогда как мне действительно нужно было только сопоставить группу (потому что у меня нет доступа к коду, стоящему за этим).